HyperFrames vs video-use 徹底比較|AI動画編集2大OSSの設計思想

AI動画編集の文脈で「HyperFrames」と「video-use」が同時に注目される理由
2026年に入り、AIで動画を作る・編集するためのオープンソースが立て続けに公開されました。なかでも実装目線で目を引いたのが、HeyGenのHyperFramesと、Browser-Useのvideo-useの2つです。どちらも「AIエージェントから扱える動画ツール」として語られますが、中身を読み込むと両者は驚くほど別物です。
私はFyveという法人で受託開発をしながら、過去にはクライアント向けにPR動画案件も受けてきました。動画は「撮る」「切る」「組み立てる」「テロップを焼く」「色を整える」という工程に分かれていて、それぞれが独立した職能です。HyperFramesとvideo-useは、この工程のどこを自動化するのかが完全に違います。本記事ではこの違いを技術スタック、設計思想、入出力、得意とする動画タイプの観点から徹底的に整理します。
以下、便宜的に「HyperFrames」「video-use」と表記します。読み終わる頃には、自社の用途でどちらを選ぶべきか、あるいは併用すべきかの判断軸が手に入るはずです。
結論:両者は同じカテゴリではない
はじめに結論を書きます。両者を同じ土俵で比較しようとすると本質を見誤ります。立ち位置で言えばこうなります。
- HyperFrames:HTMLとCSSで動画を「組み立てる」ためのレンダリングフレームワーク。ゼロから合成的に動画を生成する用途。プロダクト紹介、データ可視化、ソーシャル動画、Webサイトを動画化するなど、ジェネレーティブな動画制作が主戦場。
- video-use:撮影済みの素材フォルダを与えると、完成品の
final.mp4を返してくる「編集スキル」。トーキングヘッド、モンタージュ、チュートリアル、トラベル、インタビューなど、実写ベースの編集作業が主戦場。
つまり、HyperFramesは「合成(generative)」、video-useは「編集(cutting)」というのが最も粗い差分です。これを踏まえた上で、それぞれの中身を見ていきます。

HyperFramesとは:HTMLで動画を書くレンダリングフレームワーク
キャッチコピーと開発元
HyperFramesの公式メッセージは「Write HTML. Render video. Built for agents.」。AIアバター動画SaaSで知られるHeyGenが公開したオープンソースで、ライセンスはApache 2.0です。商用利用に追加課金や席数上限がなく、Remotionが有料ライセンスに切り替わって以降、企業利用の選択肢として急速に注目されています。
設計思想
核は4つあります。
- HTMLネイティブ:作成物の一次形式はReactコンポーネントではなくHTML。「エージェントはすでにHTMLを話す」という前提に立ち、ビルドステップを排しています
- 確定的レンダリング:同じ入力からは常に同じMP4が出る。CIに乗せる前提の作りで、回帰テスト用にGit LFS経由で参照MP4をホストしています
- Frame Adapterパターン:アニメーションランタイム(GSAP / Lottie / CSS / Three.js)を差し替え可能。フレーム精度でシークできるライブラリを選べる
- AI優先:CLIは非対話型がデフォルト。Claude Code、Cursor、Gemini CLI、Codexからスラッシュコマンド経由で叩く前提
技術スタック
- 言語:TypeScript中心(96%超)
- キャプチャ:Puppeteerでブラウザを動かしてフレームを撮り、FFmpegでエンコード
- シェーダー:WebGLによる遷移エフェクト
- 動作要件:Node.js ≥ 22、FFmpeg、Git LFS(テスト用MP4が約240MB)
パッケージ構成
モノレポで以下のように役割が分かれています。
hyperframes:CLI本体(init, preview, render, lint, transcribe, tts, doctor)@hyperframes/core:型・パーサ・ランタイム・リンター@hyperframes/engine:Puppeteer + FFmpegのキャプチャエンジン@hyperframes/producer:キャプチャ+エンコード+音声合成のフルパイプライン@hyperframes/studio:ブラウザ上の編集UI@hyperframes/player:埋め込み可能なWebコンポーネント@hyperframes/shader-transitions:WebGLシェーダー遷移集
HTMLスキーマ:data属性で時間軸を表現
HyperFramesの肝はHTMLのdata属性に時間情報を載せることです。例えば次のように書きます。
data-composition-id:構成のIDdata-start:要素が出現するフレーム/時刻data-duration:表示の継続時間data-track-index:トラックの重なり順data-width/data-height:ステージサイズ(例: 1920×1080)data-volume:オーディオの音量(0.0〜1.0)
つまり、CSSやGSAPで見た目を作り、data属性で「いつ、どこに、どのレイヤーで」を宣言するだけ。タイムラインUIを提供する代わりに、HTMLそのものをタイムラインにしてしまったわけです。これは「LLMがHTMLを書けるなら、LLMが動画を書けるはず」という発想の徹底に他なりません。
得意な動画タイプ
- プロダクト紹介動画(フェードイン、背景動画、ナレーション)
- データ可視化(アニメーション付きチャート、バーチャートレース)
- ソーシャル動画(縦9:16、キャプション同期)
- Webサイトの動画化(URLからの自動生成スキルあり)
- Remotion資産の移行(HTML構成への翻訳ガイドあり)
50以上のプリセットコンポーネントが npx hyperframes add <name> で追加でき、Instagramフォローオーバーレイやシェーダー遷移、データチャートを部品単位で組み込めます。
video-useとは:素材フォルダに対話するだけで完成品が出る編集スキル
キャッチコピーと開発元
video-useはBrowser-Useチームが公開したオープンソース。Browser-Useは「LLMでブラウザを操作する」分野の代表格で、video-useはその思想を動画編集に持ち込んだものです。提供形態はClaude CodeのSkillとして動作することが前提で、Claude本体に組み込んで使います。
設計思想:5つの柱
- テキスト+オンデマンド可視化:LLMに動画を全フレーム読ませない。文字起こしを軸に判断し、必要なときだけタイムラインビューのPNGを生成して目視代わりにする
- オーディオ主体・映像従属:話している内容を最初に確定し、映像はそのカット境界に従う
- 確認→実行→自己評価→保存:レンダリング後にもう一度自分で見直すループを内蔵
- コンテンツタイプへの先入観なし:トーキングヘッドだろうがトラベル動画だろうが、メニューやプリセットを切り替えない
- 12の厳格ルール+表現の自由:プロダクションとして守るべき制約は固定し、それ以外は自由
技術スタック
- 言語:Python中心(76%)
- 文字起こし:ElevenLabs Scribe APIで単語レベルのタイムスタンプを取得
- 動画処理:FFmpeg
- 素材取得:yt-dlp(YouTube等から素材を引っ張れる)
- アニメーション:Manim、Remotion、PIL
- 必要なAPIキー:ElevenLabs(必須)
パイプライン
- 文字起こし:単語レベルのタイムスタンプを得る
- パッキング:
takes_packed.mdとして約12KBのテキストに圧縮(フレーム単位だと約4500万トークン相当が必要になるため、テキスト主導で扱える形に変換) - LLM推論:どこを残し、どこを切るかを判断
- EDL(編集判断リスト)の生成:In/Out点とエフェクト指示を構造化
- レンダリング:FFmpegで実際にカット・色補正・字幕焼き込み
- 自己評価ループ:各カット境界でタイムラインビュー(フィルムストリップ+波形+単語ラベル)を生成し、視覚的なジャンプ、オーディオのポップ、隠れた字幕を検出。問題があれば修正→再レンダリング
ポイントはLLMに動画を「見せない」設計です。動画を読むのであり、視聴するのではない。フレームをそのままLLMに食わせると桁違いのトークンを消費するため、テキスト+必要時のみPNGダンプという軽量な交互作用に振り切っています。
得意な動画タイプ
- トーキングヘッド(自分や講師がカメラに向かって話す動画)
- モンタージュ(複数素材のテンポ良いつなぎ)
- チュートリアル動画(フィラー除去とテロップで仕上げる)
- トラベル動画
- インタビュー動画
標準で組み込まれている処理
- 「えー」「あー」「言い直し」の自動カット
- 無音の詰め
- カット箇所への30msフェード(クリックノイズ防止)
- カラーグレーディング(ウォーム・シネマティック、ニュートラル・パンチなど)
- 字幕焼き込み(デフォルトは2語ずつの大文字、TikTokなどのショート動画で見るスタイル)
- 必要に応じてManim・Remotion・PILでオーバーレイアニメーションを生成
共通点:両者がAIエージェント時代に共通して持つもの
立ち位置は別物ですが、同時期に登場したことには必然があります。両者には共通の設計DNAがあります。
- エージェントから呼ばれる前提:HyperFramesはClaude Code等のスラッシュコマンド、video-useはClaude CodeのSkillとして提供。GUIを前提としていない
- FFmpeg依存:最終的な動画書き出しは結局FFmpeg。LLMはあくまで構成判断と入出力の橋渡しを担う
- テキストベースの中間表現:HyperFramesはHTML、video-useはMarkdown(
takes_packed.mdとproject.md)。LLMに食わせやすい形式で意思決定を行う - 確定性 / 再現性:HyperFramesは入力同一→出力同一を保証、video-useは自己評価ループで仕上がりを安定化
- セッションの永続化:HyperFramesはHTMLそのものが永続化、video-useは
project.mdに進捗を保持 - 既存パイプラインとの結合容易性:FFmpegさえ動けば良いので、CIやサーバ常駐ワーカーに乗せやすい
決定的な違い:合成か、編集か
本質的な差を一覧にします。
- 入力:HyperFrames=HTMLファイル+アセット/video-use=撮影済み動画ファイルの入ったフォルダ
- 主軸:HyperFrames=視覚デザイン(CSS / GSAP / シェーダー)/video-use=音声と発話内容
- 創作行為の単位:HyperFrames=コンポーネント・トラック・タイムライン/video-use=カット・テロップ・色
- 主言語:HyperFrames=TypeScript/video-use=Python
- 主依存:HyperFrames=Puppeteer+FFmpeg+WebGL/video-use=FFmpeg+ElevenLabs Scribe
- LLMの役割:HyperFrames=コンポジションを書く(プログラミング)/video-use=EDLを判断する(意思決定)
- 得意な被写体:HyperFrames=架空の世界(プロダクトUI、データ)/video-use=現実の被写体(人、風景)
- 距離感:HyperFrames=After Effects + Remotionの後継/video-use=Premiere Pro + Descriptの後継
HyperFramesは「コードで世界を組み立てる」、video-useは「現実から要らない部分を削る」と言い換えても良いくらいの差があります。
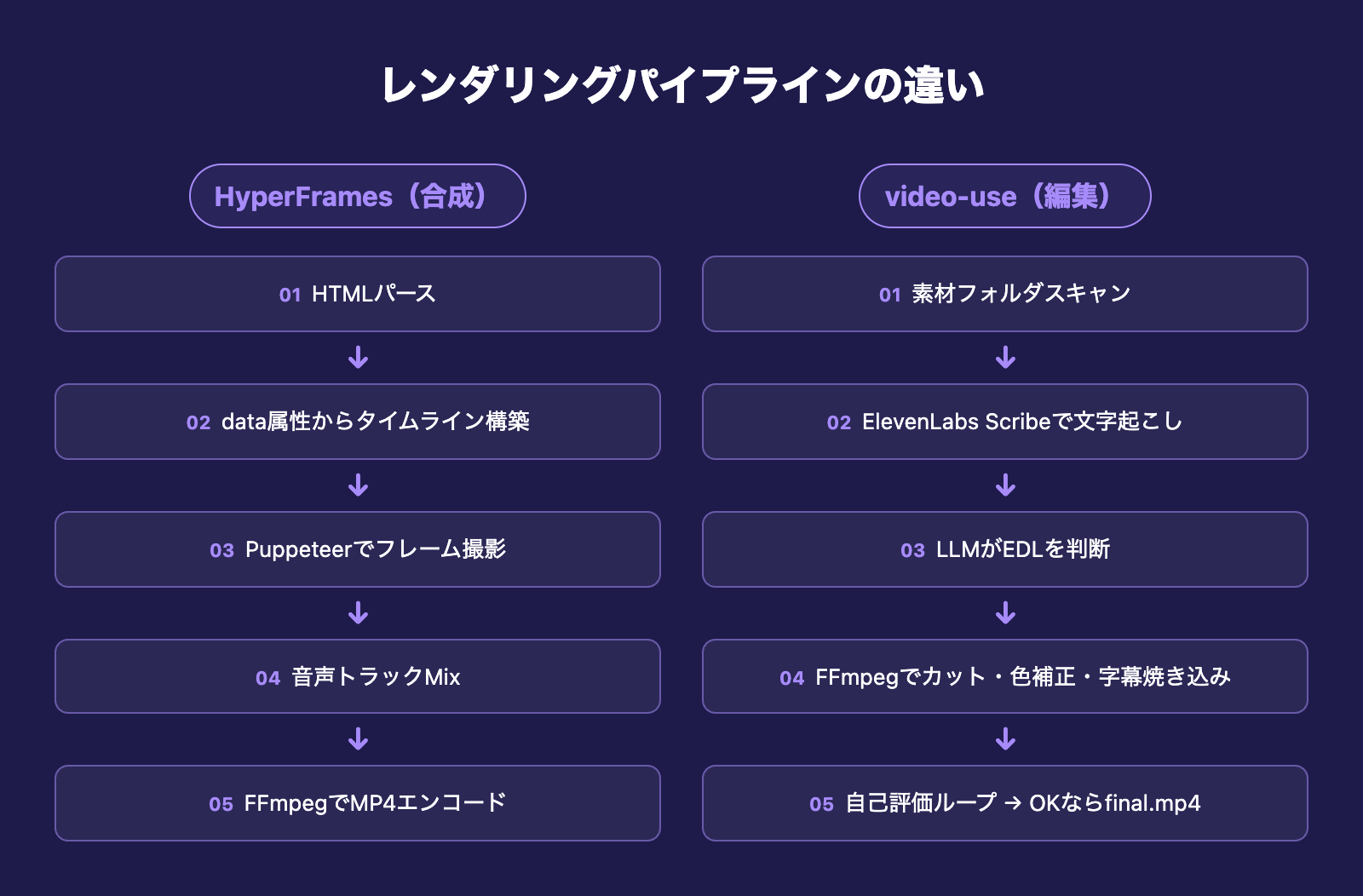
技術設計の比較:レンダリングパイプラインで見る違い
HyperFramesのパイプライン
- HTMLをパース(
@hyperframes/core) - data属性からタイムラインを構築
- Puppeteerで非ヘッドレスブラウザに描画させ、各フレームのスクリーンショットを取得
- 音声トラックをミックス
- FFmpegでMP4にエンコード
ライブプレビューはブラウザで直接DOMを再生するため、開発体験が早い。確定レンダリング時は時間軸をフレーム単位でPuppeteerが進めるため、wall-clockではなくフレーム精度で再現できます。
video-useのパイプライン
- 素材フォルダをスキャン
- 各クリップをElevenLabs Scribeに渡して単語レベルのタイムスタンプ付き文字起こしを取得
- パック化テキストをLLMに渡して残す/切るを決定
- EDLを生成
- FFmpegでカット・カラーグレーディング・字幕焼き込み
- 結果を自己評価。NGならEDLを修正して再レンダリング
HyperFramesが「描く」のに対し、video-useは「読み解いて削る」。レンダリングパイプラインの構造そのものに、対象が架空か現実かの違いが現れています。
どちらを使うべきか:4つの判断軸
軸1:入力素材があるか、ないか
撮影済みの動画素材があるなら video-use。素材がなく、ゼロから生成するなら HyperFrames。これが最も大きな分岐です。
軸2:被写体が現実か、抽象か
人間が話している、風景が映っている、現実の動きを記録した動画なら video-use の独壇場です。プロダクトのUIアニメ、グラフ、ロゴモーション、抽象的な遷移なら HyperFrames が向いています。
軸3:制作チームのスタックは何か
フロントエンド寄り(TypeScript、React、CSS)の開発チームなら HyperFrames が自然に馴染みます。Python・データ系の現場や、字幕・音声処理が日常業務にあるならvideo-useが手に馴染むはずです。
軸4:何をAIに任せたいか
「動画を新しく作ってもらいたい」場合はHyperFrames。「素材はあるので仕上げてほしい」場合はvideo-use。前者はゼロイチの生成、後者は最後の一押しの自動化です。

受託の現場から見たそれぞれの位置づけ
私は過去に、ある建設会社向けにPR動画を制作した経験があります。3分弱の本編1本+2分弱のショート版2本という構成で、撮影は提携カメラマン、編集はクラウドソーシングの編集者と分業しました。会社説明会のスライドの間に挿入したり、Instagramリール用に切り抜いたりと用途が分かれるため、最終的に複数のバリエーションを書き出す必要があります。
こうした「実写素材があり、用途別に複数バリエーションを切り出す」案件は、まさにvideo-useが想定する世界です。フィラー除去・カラーグレーディング・テロップという定型作業をAIに任せ、編集者は構成判断と最終チェックに集中する形に再設計できます。
一方で、別件のWebサイト制作では、サイトの世界観に合わせたモーションロゴやヘッダーのキネティックタイポグラフィが必要になります。こうした「ゼロから合成的に作る」用途は、HyperFramesの得意領域です。Webサイト本体をNext.jsとGSAPで作っているなら、HyperFramesのHTML+GSAPスタックは違和感なく溶け込みます。
つまり受託の現場で言えば、video-useは編集パートナーの代替、HyperFramesはモーショングラフィックス制作の代替として位置付けるのが現実的です。両方を併用するシナリオも素直に成立します。video-useで本編を仕上げ、HyperFramesでオープニング・エンディング・図解パートを生成し、最終的にFFmpegで結合する。これが2026年時点のAI時代の動画制作ワークフローのひとつの完成形だと考えています。
導入時の注意点
HyperFramesの注意点
- Node.js ≥ 22、FFmpeg、Git LFSの導入が前提(テスト用MP4が約240MB)
- 分散レンダリング機能はまだ未実装。長尺・大量並列のジョブはRemotion Lambdaのような外部基盤に劣る
- 50以上のコンポーネントは便利な一方、案件特化のテンプレートは自前で組む必要がある
- 音声合成や文字起こしは内蔵CLIにあるが、品質要件が高い場合は外部APIとの差し替えを設計に含める
video-useの注意点
- ElevenLabs APIキーが必須。文字起こしの品質と料金がそのままアウトプットの品質と料金に直結する
- 話者判別やフィラー検出は外部依存のため、対象言語・ノイズ環境で精度が変わる
- LLMが動画を「視聴」しないため、被写体の表情やカメラワークの良し悪しは判断できない(音声と単語で判断する)
- 自己評価ループで解決できる範囲には限度があるため、最終チェックは人間が行う運用にした方が安全
ライセンスと商用利用
HyperFramesはApache 2.0で完全なオープンソース、商用利用に追加課金や席数制限はありません。Remotionが大規模利用で有料ライセンスに移行したことを受け、商用プロダクトに組み込む際の選択肢としてよく挙がっています。
video-useもオープンソースですが、ElevenLabs APIの利用料金が実質的なランニングコストになります。動画素材の総時間に比例するため、長尺コンテンツを大量に処理する場合は事前に試算しておくことをおすすめします。
AIエージェント時代の動画制作はどう変わるか
HyperFramesとvideo-useをそれぞれ触ってみると、共通して感じるのは「LLMが動画制作の指揮者になりつつある」という構図です。これまではNLE(Premiere、DaVinciなど)のタイムラインに人間が線を引いていました。これからは、自然言語の指示を受け取ったエージェントが、HTMLやEDLという中間表現を介して動画を組み立てる時代です。
そのためには、動画制作の知識が「コードで表現できる形」に整理されている必要があります。HyperFramesがHTMLのdata属性で時間軸を表したのも、video-useが動画を文字起こし+EDLというテキスト中間表現に落としたのも、LLMが理解できる粒度で動画を再定義したという点で共通しています。
逆に言えば、動画制作のロジックを言語化・構造化できる現場ほど、AIによる効率化の恩恵を受けやすいということです。テンプレートが暗黙知のまま編集者の頭の中にある現場では、AIエージェントが入る余地はそれほど大きくありません。
まとめ:HyperFramesは「合成」、video-useは「編集」
- HyperFramesはHTMLで動画を組み立てるレンダリングフレームワーク。プロダクト紹介、データ可視化、ソーシャル動画など、合成的な動画制作を担う
- video-useは素材フォルダに対話するだけで
final.mp4を返してくる編集スキル。トーキングヘッド、モンタージュ、チュートリアル、インタビューなど、実写ベースの編集を担う - 共通点はAIエージェント前提・FFmpeg依存・テキスト中間表現・確定性・セッション永続化
- 決定的な違いは「合成か、編集か」。入力素材の有無、被写体が現実か抽象か、で選び分ける
- 受託の現場では併用が現実的。本編はvideo-use、オープニングや図解はHyperFrames、結合はFFmpegという構成が成立する
動画制作はAIエージェントが介在することで、構成判断と仕上げが分離されつつあります。HyperFramesとvideo-useはそのうねりを最も具体的な形で示してくれた2つです。社内に動画ニーズがある中小企業にとっては、編集パートナーへの外注フローを再設計する材料になりますし、開発会社にとってはクライアントワークの内部化のきっかけになります。どちらも触っておいて損はありません。
御社の業務に合わせたClaude Code導入支援
「AIツールを導入したが、現場で使われない」を終わらせる。
業務課題のヒアリングから設計、ハンズオン実践、運用定着まで一貫して支援します。