Claude Codeのコンテキストが消える問題の解決法

Claude Codeの「セッションが切れると全部忘れる」問題
Claude Codeは現時点で最も強力なAIコーディングエージェントの一つです。しかし、実務で使い込むほどぶつかる壁があります。セッションが切れると、それまでの文脈が全て消えるという問題です。
前回のセッションで「このファイルはこういう設計思想で作った」「このバグはこう対処した」と共有した情報が、新しいセッションではゼロからやり直し。もう一度同じ説明をしなければならない。Claude Codeの能力自体は申し分ないのに、セッション間のコンテキスト維持ができないことで、本来の生産性を発揮しきれない——これは多くのユーザーが感じている課題です。実際、Sourcegraphが2024年に実施した開発者調査では、「セッション間でのコンテキスト喪失」と「プロジェクトの詳細を毎回説明し直す必要がある」ことが、AIコーディングアシスタントに対する不満のトップに挙げられています。
この問題に対して、LlamaIndex創業者のJerry Liu氏が2026年4月にX(旧Twitter)で公開した手法が大きな注目を集めました。「LLMでパーソナルナレッジベースを構築する」というアプローチです。
この記事では、Jerry Liu氏の手法を全要素にわたって詳しく解説した上で、私自身がClaude Codeで実践しているコンテキスト維持の仕組みを紹介します。
Jerry Liu氏が提唱する「LLMナレッジベース」の全体像
Stack Overflowの2024年Developer Surveyによれば、開発者の76%がAIコーディングツールを使用中または導入を予定しています。これほど普及が進む中で、コンテキスト維持の課題は今後ますます多くの開発者に影響を与えるでしょう。
Jerry Liu氏のアプローチを一言でまとめると、「ソースドキュメントをLLMに読み込ませ、Markdown形式のWikiを自動生成・維持させる。そのWikiに対してQ&Aや品質チェックを行い、知識を継続的に蓄積する」というものです。
ポイントは、Wikiの作成・更新・整理を全てLLMが行うこと。人間はほとんどWikiを直接編集しません。LLMの領域として任せきるのが設計の肝です。
以下、Jerry Liu氏が公開した7つの構成要素を一つずつ解説します。

1. Data Ingest — ソースドキュメントの取り込みとWiki化
最初のステップは、あらゆるソースドキュメントをraw/ディレクトリに集約することです。対象は記事、論文、リポジトリ、データセット、画像など多岐にわたります。
ソースが集まったら、LLMを使ってインクリメンタルにWikiを「コンパイル」します。Wikiとは、ディレクトリ構造を持つ.mdファイルの集合体です。LLMは以下の処理を行います。
raw/内の全データの要約を生成- ドキュメント間のバックリンク(相互参照)を作成
- データを概念(コンセプト)ごとにカテゴリ分類
- 各コンセプトに対して記事を執筆
- 全ての記事を相互リンクで接続
ソースドキュメントの取り込みには、Obsidian Web Clipper(ブラウザ拡張機能)を使ってWeb記事を.md形式に変換します。さらに、ホットキー一つで関連画像をローカルにダウンロードし、LLMがローカルファイルとして画像を直接参照できるようにしています。
2. IDE — Obsidianをフロントエンドとして使う
Jerry Liu氏はObsidianをWikiの閲覧・管理用IDEとして使っています。Obsidianを通じて、以下を一元的に閲覧します。
- raw/ — 取り込んだ生データ
- Wiki — LLMがコンパイルしたMarkdown記事群
- 可視化データ — 派生した図表やスライド
重要なのは、LLMがWikiの全データを書き・維持するという点です。人間がWikiを直接編集することはほぼありません。ObsidianはあくまでRead-onlyに近い閲覧用フロントエンドです。
Obsidianのプラグインも活用しています。例えばMarp(スライドショー作成プラグイン)を使えば、LLMが生成したMarkdownをそのままプレゼンテーション形式で表示できます。
3. Q&A — RAG不要で複雑な質問に答えられる
ここがこの手法の最も興味深いポイントです。Jerry Liu氏のWikiは、約100記事・約40万語にまで成長しています。
この規模になると、Wikiに対してあらゆる複雑な質問をLLMエージェントに投げることができます。エージェントはWiki内を自律的にリサーチし、関連する記事を読み、回答を組み立てます。
驚くべきことに、高度なRAG(Retrieval-Augmented Generation)を構築する必要がないとJerry Liu氏は述べています。LLMがWiki内のインデックスファイルと各ドキュメントの簡潔な要約を自動管理しているため、この「小規模」な段階(〜40万語)ではLLMが関連データを自力で見つけ出せるのです。
これはRAGツールの開発元であるLlamaIndex創業者の発言だからこそ重みがあります。「ファンシーなRAGに手を伸ばす必要があると思っていたが、この規模ではLLMの自律的なインデックス管理で十分だった」という実体験です。
4. Output — ターミナルではなくファイルで出力する
Jerry Liu氏が強調する重要な設計判断が、LLMの出力をターミナルの文字列ではなくファイルとして保存することです。
出力フォーマットは多様です。
- Markdownファイル — テキストベースの回答・レポート
- スライドショー(Marp形式) — プレゼン資料
- matplotlib画像 — データの可視化
これらは全てObsidianで閲覧できます。そして最も重要なのが、出力をWikiに「ファイリング」して再利用するというサイクルです。自分が調べた結果や分析がWikiに追加され、次の質問の材料になる。つまり、使えば使うほどWikiが充実し、次の回答の精度が上がる好循環が生まれます。
Jerry Liu氏はこう述べています。「エージェントを使う上で最大のボトルネックは、セッション間のコンテキスト維持だ。出力をmd/htmlファイルで保存することで、ターミナルで消えるのではなくファイルとして残り、次のセッションで読み込ませればコンテキストが復元される」。
5. Linting — LLMでWikiの品質を自動チェックする
Wikiが成長するにつれて、データの整合性が課題になります。Jerry Liu氏はLLMを使った「ヘルスチェック」を定期的に実行しています。
- 矛盾する情報の検出 — Wiki内で食い違っているデータを発見
- 欠損データの補完 — Web検索を活用して不足情報を自動的に埋める
- 新しい記事候補の提案 — 既存のデータ間の興味深い関連性を見つけ、まだ記事化されていないテーマを提案
- データ整合性の向上 — 表記ゆれや分類の不統一を修正
このLintingプロセスにより、Wikiは「使い古されて劣化する」のではなく、時間が経つほどデータの品質が向上していきます。LLM自身が「次に調べるべき面白い質問」を提案してくるため、探求の方向性もWikiが導いてくれます。
6. Extra Tools — 自作ツールでWikiをさらに強化する
Jerry Liu氏はWikiの活用を加速するための追加ツールも自作しています。例として挙げられているのが、Wiki全体を対象にした検索エンジンです。
この検索エンジンには2つのインターフェースがあります。
- Web UI — 人間が直接ブラウザで検索する
- CLI — LLMがツールとして呼び出す(大規模なクエリの一部として使用)
検索エンジン自体も「Vibe Coding」(LLMとの対話によるプログラミング)で構築したと述べています。ナレッジベースが充実してくると、それを処理するための専用ツールが自然と必要になり、そのツール開発もLLMが支援するという連鎖が生まれます。
7. Further Explorations — その先にある合成データとファインチューニング
Jerry Liu氏が将来の展望として挙げているのが、合成データ生成とファインチューニングです。
現在はWikiの内容をコンテキストウィンドウに読み込ませてLLMに処理させています。しかしWikiが十分に大きくなれば、そのデータを使ってLLMのモデルの重み自体にナレッジを焼き込むことも視野に入ります。コンテキストウィンドウではなく、モデルが「知っている」状態にするということです。
さらに自然な発展形として、「フロンティアLLMへの一つの質問が、LLMチームを自動的に起動し、一時的なWikiを構築→Lint→ループ→最終レポートを生成する」というワークフローを描いています。単なる.decode()をはるかに超えた、知識構築を伴う回答生成です。Jerry Liu氏はまさにこれをClaude Codeで実践していると述べています。
PDF処理の課題とliteparse
Jerry Liu氏が併せて指摘しているのが、ネイティブのAIコーディングツールはPDF・PPTX等の非テキストファイルの処理が弱いという課題です。オープンソースのスキルが使うライブラリは、複雑なレイアウトのドキュメントから読みやすいテキストを抽出するように最適化されていません。
この課題に対してJerry Liu氏はliteparseというOSSを開発し、GitHubで公開しています。TypeScript製でPython依存ゼロ。pypdf/pymupdfの代替として、自身のローカルClaude Codeハーネスに組み込んで運用しています。
私が実践しているClaude Codeのコンテキスト維持法
Jerry Liu氏のアプローチは「Wiki全体をLLMに管理させる」という大きなフレームワークですが、私自身もClaude Codeで日常的にコンテキスト維持の仕組みを運用しています。アプローチは異なりますが、「LLMの出力をファイルとして蓄積し、次のセッションで参照する」という本質は同じです。
Before: メモリファイルだけの時代
最初はClaude Codeのメモリファイル(~/.claude/配下の自動メモリ)だけでコンテキスト管理をしていました。結果は散々で、セッション間でほぼコンテキストが引き継がれない状態でした。大まかな内容は覚えていても、実務に頼れるレベルではなく、毎回同じ背景説明をやり直す必要がありました。
After: プロジェクト単位のGitHub管理 + 3層構造
現在はプロジェクト単位でGitHubリポジトリを作り、以下の3層でコンテキストを管理しています。
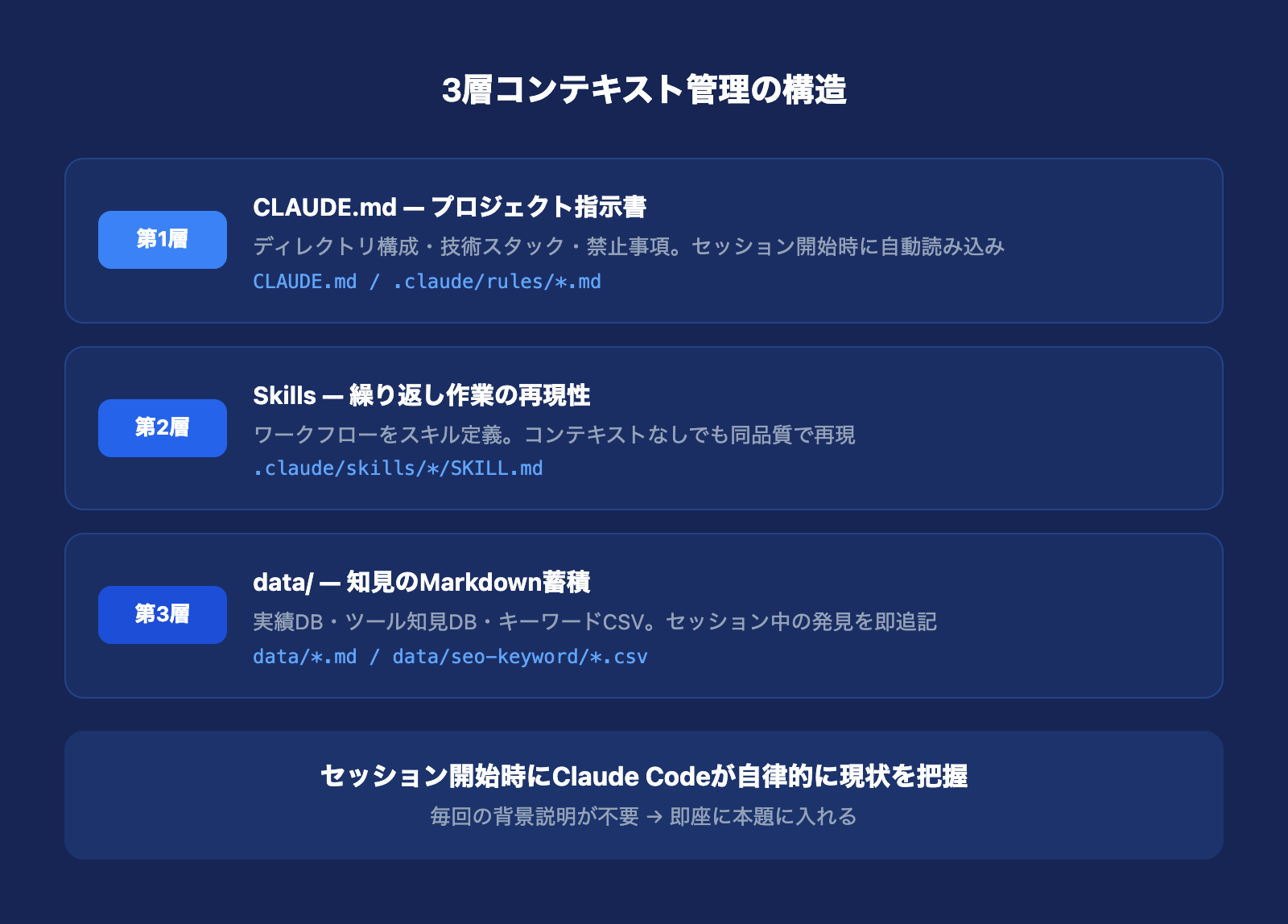
第1層: CLAUDE.md(プロジェクトの指示書)
プロジェクトのルートに置く設定ファイルです。ディレクトリ構成、技術スタック、命名規則、禁止事項など、プロジェクト全体に適用されるルールを定義します。新しいセッションを開始したとき、Claude Codeは最初にこのファイルを読むため、プロジェクトの基本的な文脈が即座に復元されます。
ただし、書き込みすぎには注意が必要です。CLAUDE.mdの記載量が一定以上増えると、コンテキスト量の増加により逆に作業精度が下がるという研究報告があります。「何を書くか」以上に「何を書かないか」の判断が重要です。

第2層: Skills(繰り返し作業のスキル化)
繰り返し行う作業はSkill(スキル)として定義します。例えば「SEO記事を執筆→サムネイル画像を生成→MicroCMSに投稿→既存記事CSVを更新」という一連のワークフローを一つのスキルにまとめています。
スキル化の最大のメリットは、コンテキストに頼らず再現可能になることです。セッションが切れても、スキルを呼び出せば同じ品質・同じ手順で作業が実行されます。「毎回思い出す」のではなく「仕組みに組み込む」ことで、コンテキスト消失の影響を最小化できます。

第3層: data/フォルダのMarkdownファイル(知見の蓄積庫)
これがJerry Liu氏のアプローチに最も近い部分です。プロジェクトのdata/フォルダに、Markdownファイルで知見を蓄積しています。
- 実績・経験データベース — 案件の実績・エピソード・数字
- AIツール知見データベース — ツールの使用体験・比較・活用方針
- キーワードCSV — SEOキーワードと検索ボリューム
- 既存記事CSV — 投稿済み記事の一覧(重複防止)
セッション中に得た新しい知見は、種類に応じて適切なファイルに即座に追記します。次のセッションでClaude Codeがこれらのファイルを読み込めば、過去の全ての蓄積を踏まえた上で作業を開始できます。

この3層構造で変わったこと

メモリファイルだけの時代と比較して、劇的に変わったのは「セッション開始時の立ち上がり速度」です。
以前は新しいセッションのたびに「このプロジェクトは何で、どういう構成で、何が終わっていて、何がまだで……」と説明する必要がありました。今はCLAUDE.md + data/フォルダを読めば、Claude Codeが自律的にプロジェクトの現状を把握し、すぐに本題に入れます。
この実感から確信しているのは、Claude Code自体の能力が上がっているのではなく、ハーネス(CLAUDE.md・Skills・ルールファイル・知見DB)の整備度が上がることで、セッションごとの出力品質が向上しているということです。
Jerry Liu氏の手法と自分の手法を比較して見えること
両者の手法を並べると、本質的な共通点と差異が浮かび上がります。
共通点:
- LLMの出力をMarkdownファイルとして永続化する
- ファイルを次のセッションで読み込ませてコンテキストを復元する
- 人間がファイルを直接編集する頻度は最小限にする
- 蓄積したデータが次の作業の品質を向上させる好循環を設計する
差異:
- Jerry Liu氏: Obsidianを閲覧フロントエンドに使い、Wiki構造(バックリンク・カテゴリ・インデックス)で知識を管理。汎用的なリサーチ用途
- 私の手法: GitHubリポジトリ内のフォルダ構造で管理。Obsidianは使わず、Claude Code CLIから直接参照。業務特化(SEO記事執筆、サービス開発等)
Jerry Liu氏のObsidian + Wiki構造は、リサーチや知識探索を主目的とする場合に特に強力です。バックリンクによる概念間の接続や、Marpプラグインによるスライド表示など、知識の「見え方」を多様に切り替えられます。一方、特定の業務フローを自動化する用途では、Skills + GitHub管理の方が再現性が高いと感じています。
どちらが優れているかではなく、用途に応じて組み合わせるのが最適解でしょう。
「コード生成」から「知識管理」へのシフト
Jerry Liu氏の投稿と同時期に、AI業界のトップ層から似たメッセージが発信されていることは注目に値します。
Andrej Karpathy氏(OpenAI共同創業者・元Tesla AI責任者)も「LLMナレッジベース」について言及し、LLMの価値はコードを生成することではなく、知識を構造化・蓄積・検索することにあるという見方を示しています。
この潮流が意味するのは、AIコーディングツールの本質的な価値が変わりつつあるということです。
- 2024年: 「AIにコードを書かせる」が主な価値。Copilot、Cursor、Claude Codeの初期利用
- 2025年: 「AIにタスクを任せる」へ拡張。エージェント、Skills、MCP連携
- 2026年: 「AIに知識を管理させる」が新たなフロンティア。ナレッジベース構築、コンテキスト維持、自律的な知識整理
McKinseyの2024年レポートでは、AIアシスタントによりコーディングタスクの生産性が20〜45%向上すると報告されています。しかしこの数字は「AIの能力」だけで説明できるものではありません。生産性向上の幅が20%から 45%まで大きく開いているのは、運用の仕組みの差が反映されていると考えるのが自然です。
Claude Codeで言えば、コードを書く能力はもう十分すぎるほど高い。差が出るのは「どう運用するか」です。プロンプトの巧みさではなく、出力の保存・整理・再利用の仕組みを持っているかどうか。これはエンジニアリングというより「知識管理」のスキルです。
実践するための具体的なステップ
ここまでの内容を踏まえて、Claude Codeのコンテキスト維持を改善するための具体的なステップを整理します。
ステップ1: CLAUDE.mdを整備する(所要時間: 30分)
プロジェクトのルートにCLAUDE.mdを作成し、以下を記載します。
- プロジェクトの概要と目的
- ディレクトリ構成
- 技術スタック
- コーディング規約(簡潔に)
- 禁止事項
書きすぎは禁物です。A4で1〜2ページ程度を目安にしてください。
ステップ2: 知見蓄積用のフォルダを作る(所要時間: 10分)
プロジェクト内にdata/やknowledge/フォルダを作り、Markdownファイルで知見を蓄積する場所を用意します。セッション中に得た重要な発見・決定・エピソードは、その場でファイルに追記するルールを定めます。
ステップ3: 繰り返し作業をSkill化する(所要時間: 1〜2時間)
最初は口頭でClaude Codeに指示しながら業務を進めます。2〜3回同じパターンが出てきたら、それをSkillとして定義します。Skillに作業手順と参照すべきファイルを明記しておけば、コンテキストがなくても同じ品質で再現できます。
ステップ4: Jerry Liu氏のWiki構築を試す(発展的)
リサーチや知識探索が多い用途なら、Jerry Liu氏のアプローチを導入する価値があります。
- raw/フォルダにソースドキュメントを集約
- Obsidian Web ClipperでWeb記事をMarkdown化
- Claude Codeに「raw/の内容を分析し、概念ごとに整理したWikiを生成して」と指示
- 生成されたWikiをObsidianで閲覧・管理
- 定期的にLLMでLinting(品質チェック)を実行
最初から完璧なWikiを作る必要はありません。ソースが10〜20件ほど溜まった段階でWikiのコンパイルを始め、使いながら育てていくのが現実的です。
まとめ — エージェントの能力は十分。差がつくのは「運用の仕組み」
Claude Codeの能力は既に十分すぎるほど高い。しかし、その能力を最大限に引き出すには、セッション間のコンテキスト維持という「運用の仕組み」が不可欠です。
Jerry Liu氏が示した「LLMナレッジベース」は、この課題に対する現時点で最も体系的なアプローチの一つです。そのエッセンスは、LLMの出力をファイルとして永続化し、蓄積したデータが次の作業の品質を向上させる好循環を設計すること。
大規模なWiki構築をいきなり始める必要はありません。まずはCLAUDE.mdの整備から。次にdata/フォルダへの知見蓄積。そしてSkill化。この3層構造だけでも、セッション間のコンテキスト維持は劇的に改善します。
AIの「能力」ではなく「運用」で差がつく時代。知識管理の仕組みを持っているかどうかが、AIを使いこなせる人とそうでない人の分水嶺になりつつあります。
御社の業務に合わせたClaude Code導入支援
「AIツールを導入したが、現場で使われない」を終わらせる。
業務課題のヒアリングから設計、ハンズオン実践、運用定着まで一貫して支援します。