Claude Codeを自己進化させる仕組み|知見蓄積の実践法

株式会社Fyve代表の田嶋です。「Claude Codeのskillsを使った自己進化システム」というコンセプトがX上で話題になっています。今回はこの仕組みを、私が実際に運用している知見蓄積ループとして具体的に解説します。
Claude Codeが「賢くなった」と感じる瞬間
Claude Codeを使い続けていると、ある時点から出力の質が明らかに上がっていることに気づきます。記事のトーンが自分の文体に近くなり、コードの実装方針が好みのアーキテクチャに沿っており、確認しなくていいことをわざわざ質問してこなくなる。
最初はモデルが賢くなったのだと思っていましたが、実際はそうではありませんでした。
変わったのはモデルではなく、ハーネス(CLAUDE.md・Skills・ルールファイル・知見DB)でした。
Claude Code自体のモデルはどのユーザーにも共通です。しかし、そのモデルに何を読ませ、どういう前提でタスクを始めさせるかは、プロジェクトごとのハーネスで決まります。ハーネスが育てば育つほど、出力品質は上がる。これが「自己進化」の正体です。
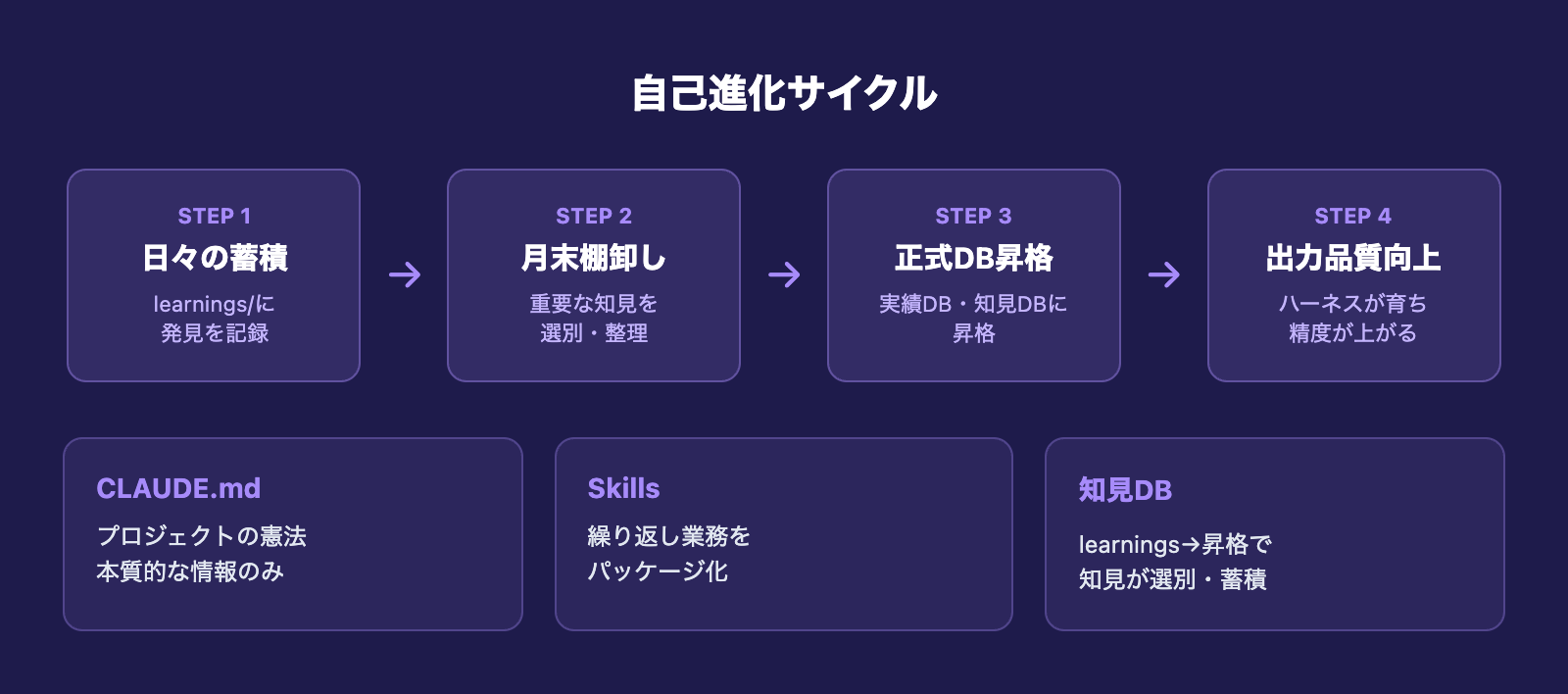
自己進化の仕組み — 3つのレイヤー
CLAUDE.md — プロジェクトの記憶
CLAUDE.mdはプロジェクトルートに置くマークダウンファイルで、Claude Codeがセッション開始時に自動的に読み込みます。ここにプロジェクトの概要、技術スタック、禁止事項、外部参照先などを記載しておくことで、毎回同じ説明をしなくて済むようになります。
「このプロジェクトはNext.js App Routerを使っていて、クライアントコンポーネントは必要な箇所だけに絞り、スタイルはこのCSSクラスに従う」——こうした文脈をCLAUDE.mdに書いておくだけで、指示の精度が大幅に上がります。
ただし、ここには注意点があります。CLAUDE.mdに書きすぎると逆効果になります。詳しくは後述します。
Skills — 繰り返す業務のパッケージ化
Skillsは特定のタスクをワンコマンドで実行するための仕組みです。例えば「SEO記事を執筆してMicroCMSに投稿する」という一連のフローを、/fyve-seo-articleのような一言で呼び出せるようにしたものです。
私が活用しているSkillsには、SEO記事作成・note記事生成・PDF生成・画像生成・フロントエンドスライド作成などがあります。これらは最初からパッケージとして用意したわけではなく、業務を繰り返す中で「このフローは毎回同じだ」と気づいた時点でSkill化しています。
知見DB — learningsから正式DBへの昇格
日々のセッションで得た発見や学びは、すぐ正式なルールファイルに書くほどではないことが多いです。そのための一時置き場が.claude/learnings/YYYY-MM.mdです。
日付・カテゴリ・内容の形式でエントリを積んでいき、月末に棚卸しをします。重要なものはdata/実績・経験データベース.mdやdata/AI開発ツール知見データベース.mdなどの正式ファイルに昇格させ、不要なものは削除する。このサイクルで知見が選別・整理されていきます。
実際にこの昇格を何度もやってみると、ハーネスが着実に精度を増していくのが実感できます。
実践している蓄積サイクル
私が回しているサイクルを具体的に書くと、次のようになります。
- 日々: セッション中に気づいたことをlearningsに追記(ルールの変更、ツールの新発見、業務フローの改善点など)
- 月末: learningsを読み返して棚卸し。重要なものは正式DBやルールファイルに昇格、不要なものは削除
- 随時: ルールへのフィードバックを受けたら、該当ファイルを即時更新
このサイクルで特に効果を感じているのが、「バズ記事を見て一歩先を試す → 知見蓄積」の流れです。
X上では「Claude Code Self-Evolving System」のような概念が定期的に話題になります。読んでみると面白いのですが、多くの場合、具体的な実装方法まで踏み込んでいません。「ハーネスを整備することで自己進化する」と書いてあっても、どのファイルに何を書けばいいかは書かれていない。
少し考えれば、その一歩先は自分で試せます。そしてアイデアがあればAIで即形にできる。試した結果をlearningsに記録しておけば、次のセッションから活きる知見になります。「情報収集 → アイデア → 即実装 → 知見蓄積」のサイクルがAIによって高速に回るようになっていくのが、この仕組みの本質的な強みです。
CLAUDE.mdに書きすぎると逆効果になる
CLAUDE.mdの重要性を説明した後でこれを言うのは矛盾して聞こえるかもしれませんが、書きすぎは逆効果です。
ある研究によると、CLAUDE.mdへの記載量が一定以上増えると、コンテキスト量の増加により作業精度が下がるという傾向が確認されています。「情報をたくさん渡せば渡すほどいい」わけではなく、モデルが処理する情報量には適切な範囲があります。
私が実践している方針は次のとおりです。
- CLAUDE.mdにはプロジェクト全体の概要・構造・禁止事項など、セッションをまたいで変わらない本質的な情報のみ記載する
- 特定の業務フローの詳細はSkillsに切り出す
- 一時的な発見・方針変更はlearningsに記録し、確立したものだけをルールファイルに昇格させる
CLAUDE.mdは「何でも書き込む場所」ではなく、「プロジェクトの憲法」です。本当に重要なことだけを、簡潔に記述する。この原則が精度を保つ上で重要です。
Skillsの本質は「おすすめ一覧」ではない
「Claude CodeのおすすめSkills」を検索すると、人気スキルの一覧を紹介する記事が多く見つかります。参考にはなりますが、それよりも大切なのは自分の業務をSkill化するプロセスそのものです。
私が実践しているアプローチは次のとおりです。
- まずは口頭で一つずつClaude Codeに指示しながら業務を進める
- 同じような指示を繰り返している業務パターンが見えてきたらSkill化して自動化
- 何度も使う中で見つかった問題点を修正・改良してブラッシュアップ
この流れを支えるのがskill-creator(スキルクリエイター)です。skill-creatorは新しいSkillを設計・作成するための専用スキルで、私はこれを必須スキルだと考えています。「このフローをSkill化したい」と思ったとき、skill-creatorに相談すれば、スキルの設計から実装まで一緒に進められます。
GitHubで公開されているスターの多い人気スキルを収集し、中身を読んで理解した上で、自分のワークフローに合うよう改良して使う。これも有効な活用法です。ゼロから作るだけでなく、既存のものを自分用にチューニングするのも立派なSkill運用です。
まとめ — AIが進化するのではなく、あなたのワークフローが進化する
Claude Codeの「自己進化」とは、モデルが賢くなることではありません。ハーネスが整備されることで、あなたのワークフローが進化していくことです。
CLAUDE.mdに本質的な文脈を書き、繰り返す業務をSkillsにパッケージ化し、日々の発見をlearningsに記録して月末に棚卸しする——このサイクルを回し続けることで、Claude Codeは「よくわからないAIツール」から「自分の業務を深く理解したパートナー」に変わっていきます。
大事なのは、最初から完璧なハーネスを作ろうとしないことです。使いながら少しずつ育てていく。そのプロセス自体が、Claude Codeを活用できるようになる最短ルートだと感じています。
御社の業務に合わせたClaude Code導入支援
「AIツールを導入したが、現場で使われない」を終わらせる。
業務課題のヒアリングから設計、ハンズオン実践、運用定着まで一貫して支援します。