Claude Opus 4.7|4.6から何が変わった?実務影響まで

2026年4月16日、AnthropicがClaude Opus 4.7をリリースしました。Opus 4.6のリリースからわずか2ヶ月での大型アップデートで、コーディング・ビジョン・エージェント性能が軒並み底上げされています。私は2025年10月のOpus 4.6登場以来、Claude CodeのMax 20xプランをメイン開発ツールとして使い続けてきた立場として、今回のアップデートは「触った瞬間に違いがわかる」レベルだったので、公式発表の数値と実務で感じた変化をあわせて整理しておきます。
この記事では、Opus 4.7で何が変わったのか、ベンチマーク・新機能・破壊的変更・料金・乗り換え時の注意点を、公式情報と実務者視点で解説します。
Claude Opus 4.7とは|2026年4月16日リリースの最新フラグシップ
Claude Opus 4.7は、Anthropicが2026年4月16日に公開した最新のフラッグシップモデルです。モデルIDは claude-opus-4-7、コンテキストウィンドウ1M(100万)トークン・最大出力128kトークンという仕様はOpus 4.6を踏襲しつつ、モデル内部の推論性能とビジョン能力、エージェント動作に大きな改善が入っています。
位置づけとしては「Opus 4.6の正当進化版」で、価格(入力$5 / 出力$25 per 1M tokens)は据え置きです。API・Claude.ai(Pro / Max / Team / Enterprise)・Amazon Bedrock・Google Cloud Vertex AI・Microsoft Foundryで同時提供されており、エンタープライズ環境でもすぐ使える体制で出てきました。
私はOpus 4.6を半年近くメイン運用してきましたが、今回のアップデートで特に気になっていた「思考予算(thinking budget)」周りの挙動が刷新され、長時間稼働のエージェント用途が一段階洗練された印象です。
Opus 4.6からの性能向上|ベンチマークで何がどれだけ伸びたか
Opus 4.7の強みは「コーディング」「視覚」「長時間エージェント」の3領域にまたがります。公式が公表した主要ベンチマークの数字を並べると、改善幅の大きさがはっきり見えます。
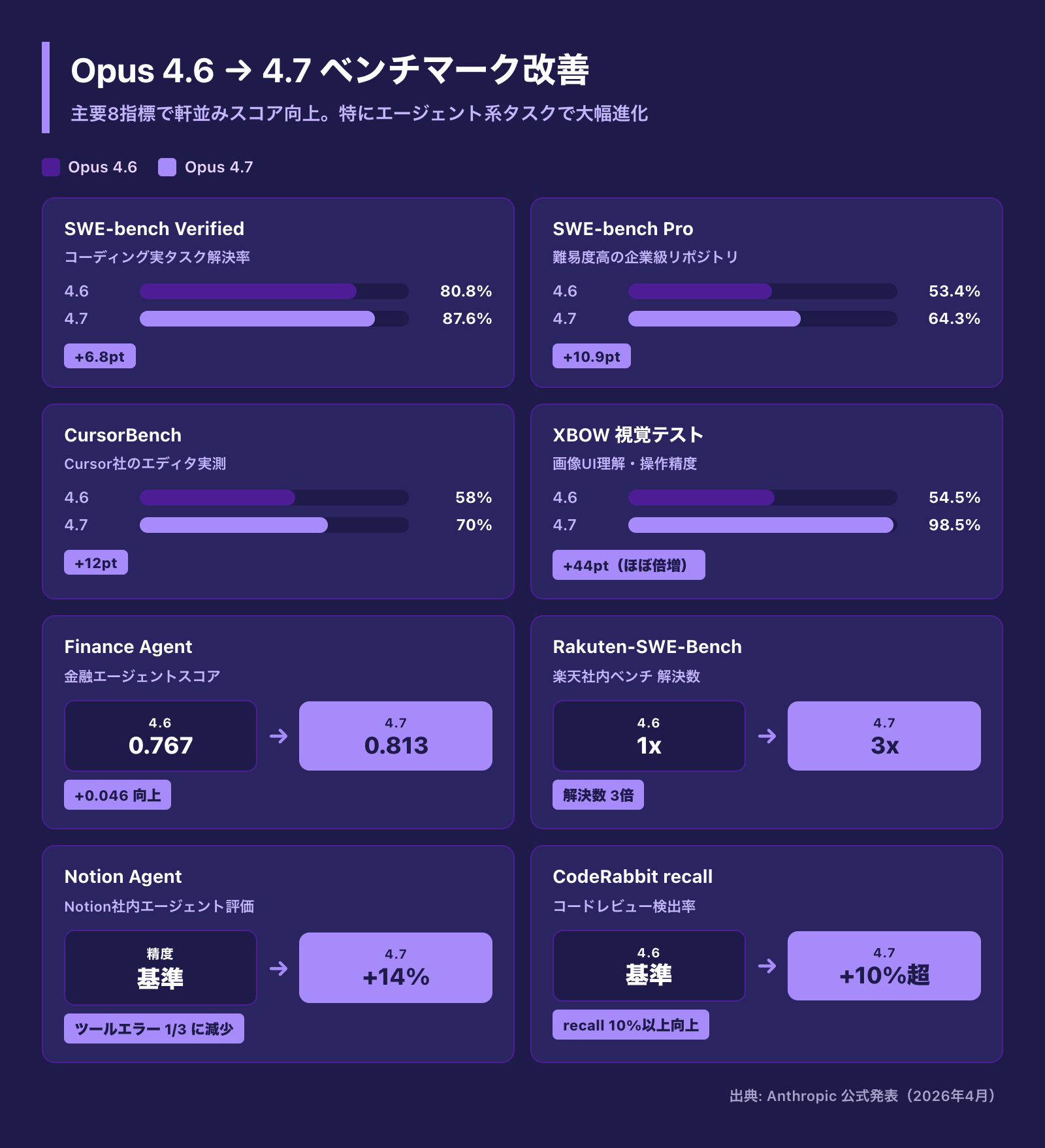
特に重要なのが、業界標準のコーディング評価であるSWE-bench系での伸びです。
- SWE-bench Verified: 80.8%(4.6)→ 87.6%(4.7)。Gemini 3.1 Proの80.6%を大きく引き離し、現行モデルで事実上のトップ
- SWE-bench Pro(本番相当タスク): 53.4%(4.6)→ 64.3%(4.7)。GPT-5.4(57.7%)、Gemini 3.1 Pro(54.2%)をいずれも上回る
- CursorBench: 58%(4.6)→ 70%(4.7)。IDE統合での実戦性能が12ポイント改善
- Rakuten-SWE-Bench(本番プロダクションタスク): 解決数が4.6比で約3倍。コード品質・テスト品質指標も二桁%の改善
- XBOW視覚能力テスト: 54.5%(4.6)→ 98.5%(4.7)。UI操作や画像解析タスクでの認識力がほぼ別物
- CodeRabbitレビュー精度: PRレビューの再現率(recall)が10%以上向上。複雑PRで4.6が見逃していたバグを拾うようになった
- Notion Agent(Computer Use): タスク精度14%改善、ツール呼び出しエラーが約1/3に
- Finance Agent(General): 0.767 → 0.813。金融・法務領域のGDPval-AAでも過去最高スコア
特筆すべきは「4.6でもSonnet 4.6でも解けなかったコーディングタスクを、4.7は解ける」というケースが93タスク中4件あった点です。単なる精度上乗せではなく、到達可能な問題領域そのものが広がっているということで、私の実務でも「4.6だと何度かリトライさせていた複雑なリファクタリングが、4.7では一発で通る」場面が増えています。
また、ドキュメント読解系のエラー率が21%減ったとAnthropicは説明しており、長文資料を読ませて分析させる場面の信頼性も底上げされています。
Claude Opus 4.7の新機能|高解像度ビジョン・xhigh・タスクバジェット
Opus 4.7には、ベンチマーク数値だけでは伝わらない「開発体験を変える」新機能がいくつか入っています。実務で意味のあるものから順に見ていきます。
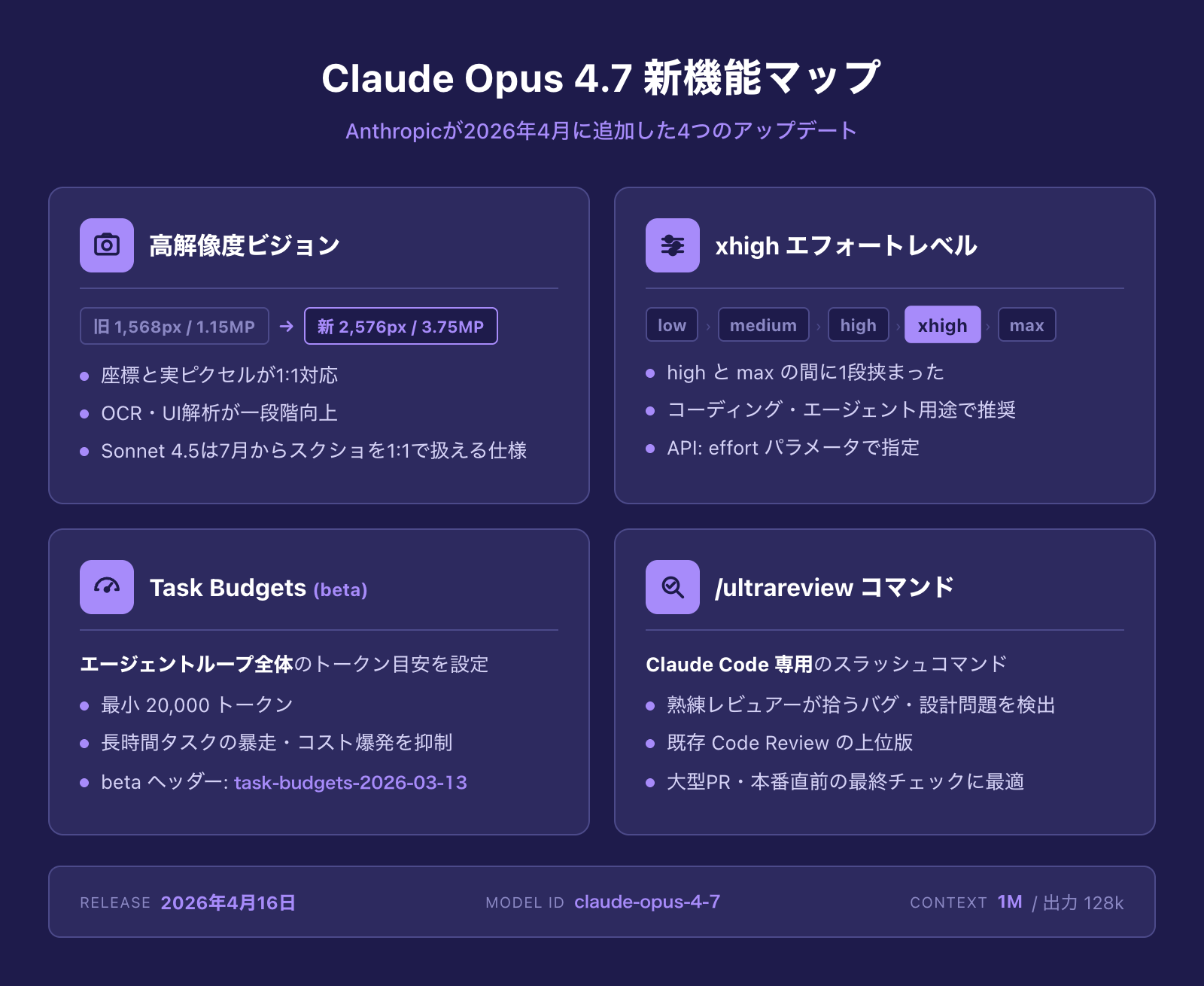
高解像度画像サポート(2,576px / 3.75MP)
これまでのClaudeシリーズは画像の長辺が1,568ピクセル(1.15メガピクセル)までだったのに対し、Opus 4.7は2,576ピクセル(3.75メガピクセル)まで一度に処理できます。実に3倍以上の画素数で、しかもモデル側の座標と実ピクセルが1:1対応になったので、「画像の特定の場所を指さす」「座標を返す」系のタスクでスケール変換の計算を挟まずに済むようになりました。
私の用途だと、クライアントから受け取る契約書のスキャン画像やGoogle Search Consoleのダッシュボードスクリーンショットを読ませる場面で、細部の文字の読み取り精度が明確に上がっています。computer use系エージェントやスクリーンショット駆動の自動化を組んでいる人ほどインパクトが大きい改善です。
新しい「xhigh」エフォートレベル
Opus 4.7では、思考の深さを制御する effort パラメータに xhigh が追加されました。従来は low / medium / high / max の4段階でしたが、high と max の間に1段挟まった形です。コーディング・エージェント用途ではこの xhigh が推奨デフォルトになっており、「max ほどトークンを使いたくないが、複雑な問題では high では足りない」というケースをカバーします。
私はOpus 4.6時代に /effort high をsettings.jsonでデフォルト化していた口ですが、4.7では xhigh に上げてもMax 20xプランの体感トークン消費は大きく変わっていません。複雑なタスクだけ自動で深く考える挙動に寄ったおかげで、プラン内でのヘッドルームが広がった印象です。
タスクバジェット(public beta)
Task Budgetsは、エージェントループ全体(思考・ツール呼び出し・ツール結果・最終出力のすべて)に対して「このくらいのトークンで完了してほしい」という目安をモデルに伝える機能です。モデルは残りバジェットをカウントダウンしながら作業を進め、予算が尽きる前にタスクを畳みに行きます。
これは max_tokens(1リクエストあたりのハードキャップ)とは別物で、長時間エージェントの「走りすぎ」を防ぐためのソフトキャップ的な仕組みです。最小バジェットは20,000トークン、betaヘッダー task-budgets-2026-03-13 を付けると有効になります。
/ultrareview コマンド(Claude Code)
Claude Code側には、Opus 4.7に合わせて /ultrareview コマンドが追加されました。人間の熟練レビュアーが引っかけるようなバグ・設計上の問題点を集中的に洗い出す専用レビューセッションで、既存のCode Review機能の上位版という位置づけです。私は普段からAIコードレビューを「ガイドライン×多層独立レビュー」で組んでいるので、このコマンドは独立した最終チェック層として組み込みやすい設計になっています。
Opus 4.7の破壊的変更|APIユーザーが注意すべき点
Opus 4.7は「ただ差し替えればOK」ではありません。Messages APIレベルでいくつか破壊的変更があり、既存コードがそのままだと400エラーになるケースがあります。Claude Managed Agents経由なら影響はほぼゼロですが、APIを直接叩いているなら以下を押さえてください。
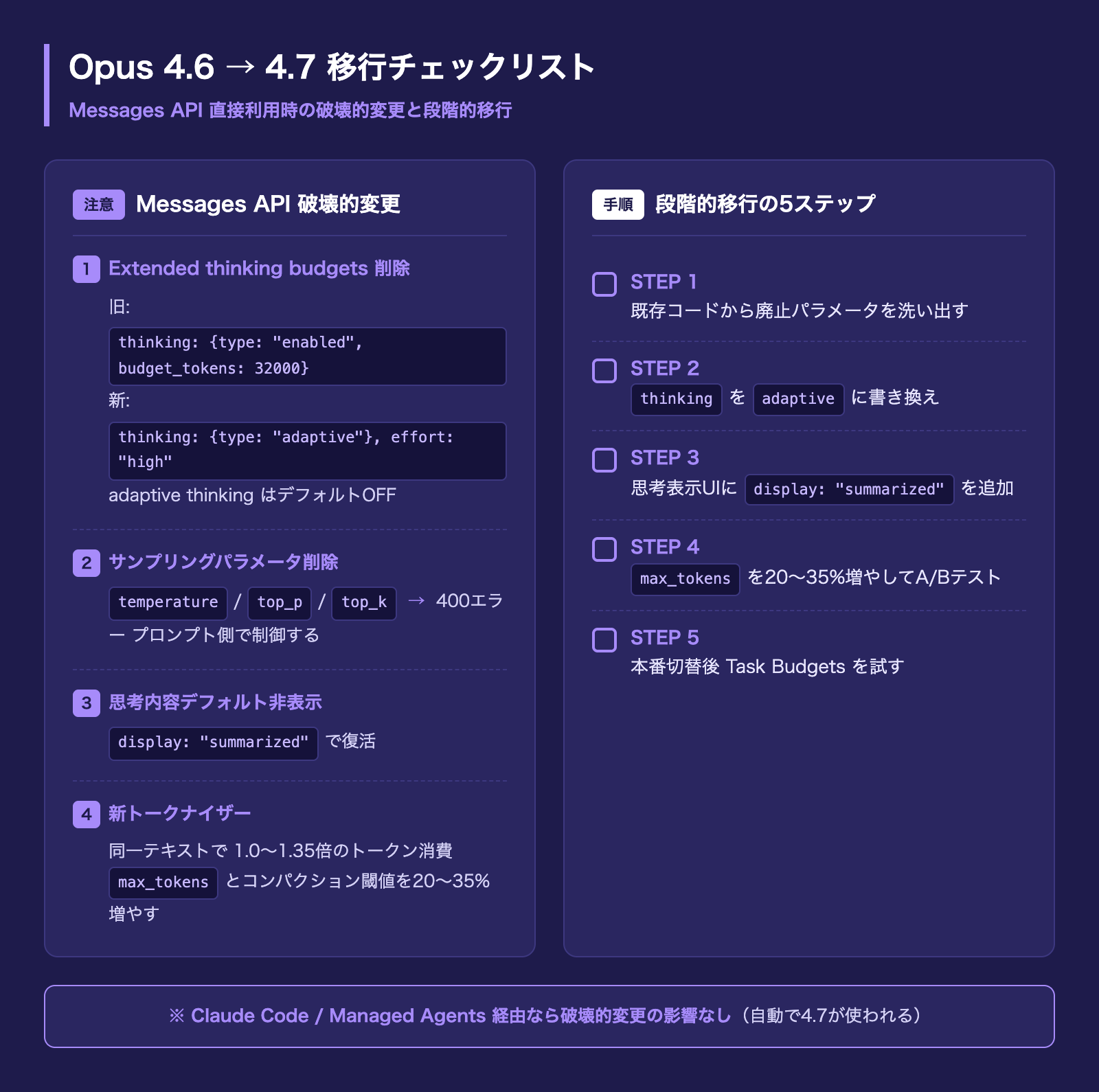
Extended thinking budgets の廃止
これまでの thinking: {type: "enabled", budget_tokens: N} は400エラーになります。Opus 4.7では adaptive thinking(自動で深さを調整する方式)が唯一のthinking-onモードで、制御は前述の effort パラメータに集約されました。さらに adaptive thinkingはデフォルトOFF なので、明示的に thinking: {type: "adaptive"} を指定しないと思考なしで動きます。
サンプリングパラメータの廃止
temperature / top_p / top_k にデフォルト以外の値を設定すると400エラーになります。挙動を制御したい場合はプロンプト側でコントロールする方針に振られました。temperature=0 を決定論目的で入れていた実装は、この機会に削除するのが安全です。
思考内容はデフォルトで非表示
Opus 4.7では thinking フィールドがデフォルトで空 になります。ユーザーに思考過程を見せていたUIをそのまま流すと、出力開始まで無言の時間が長く感じられる副作用があるので、表示したい場合は明示的に display: "summarized" を指定してください。
新トークナイザー(1.0〜1.35倍)
Opus 4.7は新しいトークナイザーを採用しており、同じテキストでも1.0〜1.35倍程度トークンを消費します。/v1/messages/count_tokensの返り値もOpus 4.6とは変わるので、既存の max_tokens やコンパクション条件は余裕を持たせて見直すのが安全です。1Mコンテキストは従来どおりlong-contextプレミアムなしで使えます。
実務で感じるOpus 4.7の変化|挙動の違い
ここまでは公式情報ベースの話ですが、実際にClaude Codeで使ってみて私が感じている変化も書いておきます。Anthropic公式もリリースノートで「behavior changes」として明記しており、既存プロンプトの手直しが必要になる場面があります。
- 指示への忠実度が上がった: 1項目のルールを別の項目に勝手に一般化しない。「xならyせよ」とだけ指示すれば、類似ケースには勝手に適用しない
- 返答の長さがタスクに合わせて動的に決まる: 無駄に詳しく書く癖が減り、簡単な質問には簡潔に返してくる
- ツール呼び出しの回数が減る: 推論で片付けられる場面は推論で処理する。effortを上げるとツール使用量も増える
- トーンが直接的・意見の明確な方向に: Opus 4.6の柔らかい同意トーンより、断定的で推薦を明示する書き方にシフト
- 長時間エージェントでの進捗報告が増えた: 無言で長時間走るのではなく、定期的に現在地を返してくる
- サブエージェント生成が減少: デフォルトでは不必要にサブエージェントを立ち上げない。必要ならプロンプトで明示する
私の場合、CLAUDE.mdに「進捗をこまめに報告せよ」といったscaffoldingを入れていたのですが、4.7ではそれを外しても自然に報告を挟んでくるようになりました。既存プロンプトの冗長な指示は一度外して様子を見ると、素の4.7の挙動が把握しやすいと思います。
思考予算問題の解消|私のOpus 4.6での課題が消えた
2026年3〜4月にかけて、Opus 4.6で「思考予算のデフォルトがmediumに落ちたことで、複雑なタスクの品質が下がった」という現象が広く報告されました。GitHub issue #42796で6,852セッション・17,871思考ブロックを分析した結果、思考の深さが落ちるとモデルが「調査優先」から「編集優先」にシフトし、ファイルを読まずに編集に飛びつくという傾向が確認されています。
私自身もここ数週間、簡単なタスクは普通に動くのに、複雑なコーディングや重いコンテキストを扱うタスクでガイドライン違反のミスが増えていると体感していました。対策として "effortLevel": "high" をsettings.jsonでデフォルト化していたのですが、Opus 4.7ではthinking budgetという概念自体が廃止され、adaptive thinking + effortパラメータの組み合わせに一本化されました。
実際に4.7に切り替えてから、「また同じミスをしている」と感じる場面がほぼなくなり、重いコンテキストの記事執筆ワークフローでもルール遵守度が明確に上がっています。このあたりは4.6で苦しんでいた人ほど乗り換えメリットを強く感じるはずです。
料金・アクセス方法|4.6から据え置き
Opus 4.7は性能が上がっても価格は4.6から据え置きです。内訳は以下の通りで、プロンプトキャッシングで最大90%、バッチ処理で50%の節約ができる構造も継続しています。
- 入力: $5 / 1M tokens
- 出力: $25 / 1M tokens
- US-only inferenceを選ぶ場合: 1.1倍
- プロンプトキャッシング: 最大90%節約
- バッチ処理: 50%節約
Claude.aiのPro / Max / Team / Enterpriseサブスク、Claude API、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundryのいずれからもアクセス可能です。前述の新トークナイザーで同一テキストのトークン数が1.0〜1.35倍になるため、APIコスト見積もりは少し余裕を持って組むのが安全です。
中小企業でOpus 4.7をどう活用するか
ここまで技術的な変化を整理してきましたが、私が日々中小企業向けにAI業務効率化を受託している観点からも、Opus 4.7は「ビジネス活用の現実解」としての完成度が一段上がった印象です。
特にコスト効率の点で重要なのは、同じ価格で推論精度が上がったため、今まで「Opus 4.6では失敗が多くて使えなかった」タスクが本番投入可能になることです。介護・建設・クリニックなど、書類作成や議事録整理、顧客対応のテンプレ自動生成といった業務で、失敗コストが下がれば業務への組み込み範囲が一気に広がります。
高解像度ビジョンの改善は、手書き記録のOCRや図面・カルテの読み取りといった現場ワークで効いてきます。私が開発したデイサービス向けの記録システムでは、手書きメモのOCR精度がそのままシステム全体の使い勝手を決めるので、こうしたビジョン改善は直接成果につながる領域です。
一方、運用面ではトークン消費が1.0〜1.35倍に増える点を踏まえ、既存のクラウドコスト見積りを更新する必要があります。Claude Codeを導入している企業は、Max 20xプランやManaged Agentsを使っている限り大きな影響はありませんが、API直叩きのワークフローを組んでいるところは月次コストをモニタリングしながら切り替えるのが安全です。
Claude Opus 4.7は「乗り換えるべき」か
結論から言うと、Claude CodeでOpus 4.6を使っているユーザーは、今すぐ4.7に切り替えて問題ありません。Claude Code側は自動で4.7が使われるようになるので、APIの破壊的変更を気にする必要がない一般ユーザーにとっては、性能向上だけを受け取れる純粋なアップデートです。
一方、Messages APIを直接使って独自エージェントを組んでいる企業は、以下の手順で段階的に移行するのがおすすめです。
- extended thinking budget・サンプリングパラメータを使っている箇所を洗い出し、adaptive thinking + effortに書き換える
- thinking フィールドを表示しているUIは
display: "summarized"を指定 - max_tokens とコンパクション閾値を新トークナイザーに合わせて20〜35%多めに確保
- 非本番環境でA/Bテストし、既存プロンプトの冗長な指示を外した素の挙動を確認
- 本番切り替え後、Task Budgets betaを試して長時間エージェントのコスト最適化を検討
私自身もClaude Codeの業務ワークフロー全体を4.7ベースに更新中で、特にSkills・ルールファイル・ハーネス周りとの相性が非常に良い印象です。Claude Codeを業務に組み込んでいる組織ほど、このアップデートの恩恵を具体的に受け取れるはずです。
最新のAIモデルは性能が上がるたびに「できることの境界線」が動きます。Opus 4.7で一番変わったのは、この境界線が実務タスクに対して一段越えてきた点だと思っています。自社の業務プロセスで「今まで4.6では自動化しきれなかった領域」があれば、このタイミングで再検証する価値があります。
Opus 4.6との比較や基本的な使い分けは、以下の記事で詳しく解説しています。

御社の業務に合わせたClaude Code導入支援
「AIツールを導入したが、現場で使われない」を終わらせる。
業務課題のヒアリングから設計、ハンズオン実践、運用定着まで一貫して支援します。