Claude Codeでショート動画編集を自動化した実装記録

毎日のように動画素材を撮っているのに、編集に時間が取れず月に1〜2本しか投稿できない――。Claude Codeでショート動画編集を自動化すれば、素材をフォルダに入れて1コマンド打つだけで、縦9:16の完成動画と4プラットフォーム分の投稿文が同時に出てきます。
本記事では、動画コンテンツを発信する事業者向けに先日納品した「ショート動画自動編集パイプライン」の構築実例を、技術的な工夫と運用設計の両面から記録します。素材を入れてから完成まで実測1〜3分、月額ランニングコストは500〜1,500円程度に収まる仕組みです。
動画コンテンツ発信者の「編集ボトルネック」をどう解消したか
今回ご依頼いただいたのは、動画コンテンツを発信されている事業者の方でした。日々のショー素材は毎日のように撮影できているものの、編集工程に時間を取られて月1〜2本しか投稿できないというのが当初のお悩みでした。
編集の中身を分解すると、おおむね以下の作業に分かれます。
- インタビュー音声の文字起こし(手作業だと数十分)
- 「えー」「あのー」などのフィラー語と長い沈黙のカット
- フレーズ単位での字幕入れ
- 複数のパフォーマンス素材から見せ場を抜粋して連結
- BGMを乗せる(インタビューは控えめ、本番は強め)
- ロゴエンディング挿入
- 4プラットフォーム分(Instagram Reels / TikTok / YouTube Shorts / X)のキャプション執筆
- 業態に合わせたハッシュタグ選定
これを毎日1本ペースでやろうとすると、撮影と同じくらいの時間が編集に消えます。1本15分以内、できれば数分で済むパイプラインを作ることが今回のゴールでした。
納品した仕組みの全体像
最終的に納品したのは、Claude Codeで動く「demo-project」というフォルダー式パッケージです。クライアント側で必要な操作は以下の3ステップだけです。
- その日の動画素材を所定のフォルダに入れる
- ターミナルで
claude起動 →「ショート動画を作って」or/gen-shortと入力 - Claudeが素材構成とBGMの選択肢を提示するので、選んで「OK」と返す
あとは自動で文字起こし → カット → 字幕焼き込み → ショー組み立て → BGMミックス → 投稿文生成 まで一気通貫で走ります。出力は次の2つです。
- preview.mp4: 完成動画(縦9:16 / 1080×1920 / 30〜45秒 / 字幕・BGM焼き込み済み)
- caption-kit-*.md: 4プラットフォーム分の投稿文・ハッシュタグ・推奨投稿時間
ターミナルにも投稿文の全文が表示されるので、コピペでSNSにそのまま貼れるようにしています。
技術スタック: 標準ライブラリだけで完結させた理由
裏側で動いている技術は意外とシンプルです。
- Claude Code: スキル機構で対話フローを管理
- Python 3.10+: 標準ライブラリのみ(
urllib.requestでmultipart POST自前実装) - ElevenLabs Scribe API: 日本語文字起こし(無料枠で月20〜30分カバー)
- ffmpeg(libass付き): 動画切り出し・字幕焼き込み・BGMミックス
当初はOSSの汎用動画編集ツール「video-use」を土台にする想定でしたが、最終的にはクライアントPCに渡すフォルダだけで完結する形に作り直しました。理由は2つあります。
1つ目は、外部スキルへの依存を減らすほど、クライアント環境の再現性が上がるからです。「video-useもインストールしてください」が増えると、初日のセットアップで詰まる確率が跳ね上がります。今回の納品では、必要なものは Claude Code + Python + ffmpeg の3つだけに絞りました。
2つ目は、Pythonのrequestsパッケージすら入れなくて済むようにしたかったから。urllibでmultipart/form-dataを自前で組めば、追加インストール不要でElevenLabs Scribe APIを叩けます。pip install を1回もせずに動く納品物にすることで、「APIキーを.envに貼って、ffmpegを入れて、終わり」というシンプルさを実現できました。
工夫1: 日付フォルダ+サブフォルダで「素材の振り分け曖昧性」をゼロに
動画自動化で最初に詰まるのは、実は技術ではなく素材の置き場所です。「intro.mov」と「show1.mov」を直置きで並べると、ファイル名を間違えただけで動かなくなります。クライアントが毎日触る運用では致命的です。
今回採用したのは、日付フォルダの中にサブフォルダを切る運用です。
input/2026-05-13/
├── intro/ ← 前半トーク動画(1本)
├── show/ ← ショー本番動画(複数本)
└── outro/ ← 後半トーク動画(任意、空でも可)この構造にしてから、ファイル名は何でもよくなりました。IMG_3811.MOVのままドラッグ&ドロップでOKです。フォルダの位置で役割が決まるので、ファイル名を考える手間も、ファイル名を間違えるリスクもありません。
さらに「ショート動画を作って」とClaudeに話しかけると、今日の日付で自動的にフォルダを作って「ここに入れてください」と案内してくれます。同じ日に2本目を作る時は「新規 / 既存どっち?」と聞いてくれて、-2 -3 と連番サフィックスが付くようにしました。

工夫2: BGMの「ducked」モード ― メリハリを音量で作る
BGMの扱いには3つの選択肢があります。
- A: ショー本番のみBGM(インタビューは原音)
- B: 全体に同じ音量でBGM
- C: メリハリ(インタビュー控えめ、ショー強め)
クライアントが希望したのはCのメリハリ運用。これを実装したのが「duckedモード」です。動作はこんな感じになっています。
- 0〜7秒(インタビュー前半): BGM音量0(声がメイン)
- 7〜15秒(インタビュー後半): BGMがじわっとフェードイン(8秒のランプ)
- 15〜32秒(ショー本番): BGM最大音量、base音声はミュート
- 32〜35秒(ショー終盤): BGMがフェードアウト(3秒のランプ)
- 35秒〜(ロゴ): 完全無音
面白かったのは「ショー区間でbase音声をミュートする」工夫です。最初の試作では、ショー素材の元音声(観客のざわめき、MCの声、元のBGM)を残したまま追加のBGMを乗せていました。結果は、二重音声で追加BGMが埋もれて聞こえないというものでした。
クライアントの「BGMが全然聞こえない」というフィードバックを受けて、ショー区間だけbase音声を0にする時間制御を追加。ffmpegのvolumeフィルタを時間関数if(between(t, start, end), 0, 1)で制御することで、滑らかな切替を実現しています。境界の0.3秒をクロスフェードにしているので、ぶつ切り感もありません。

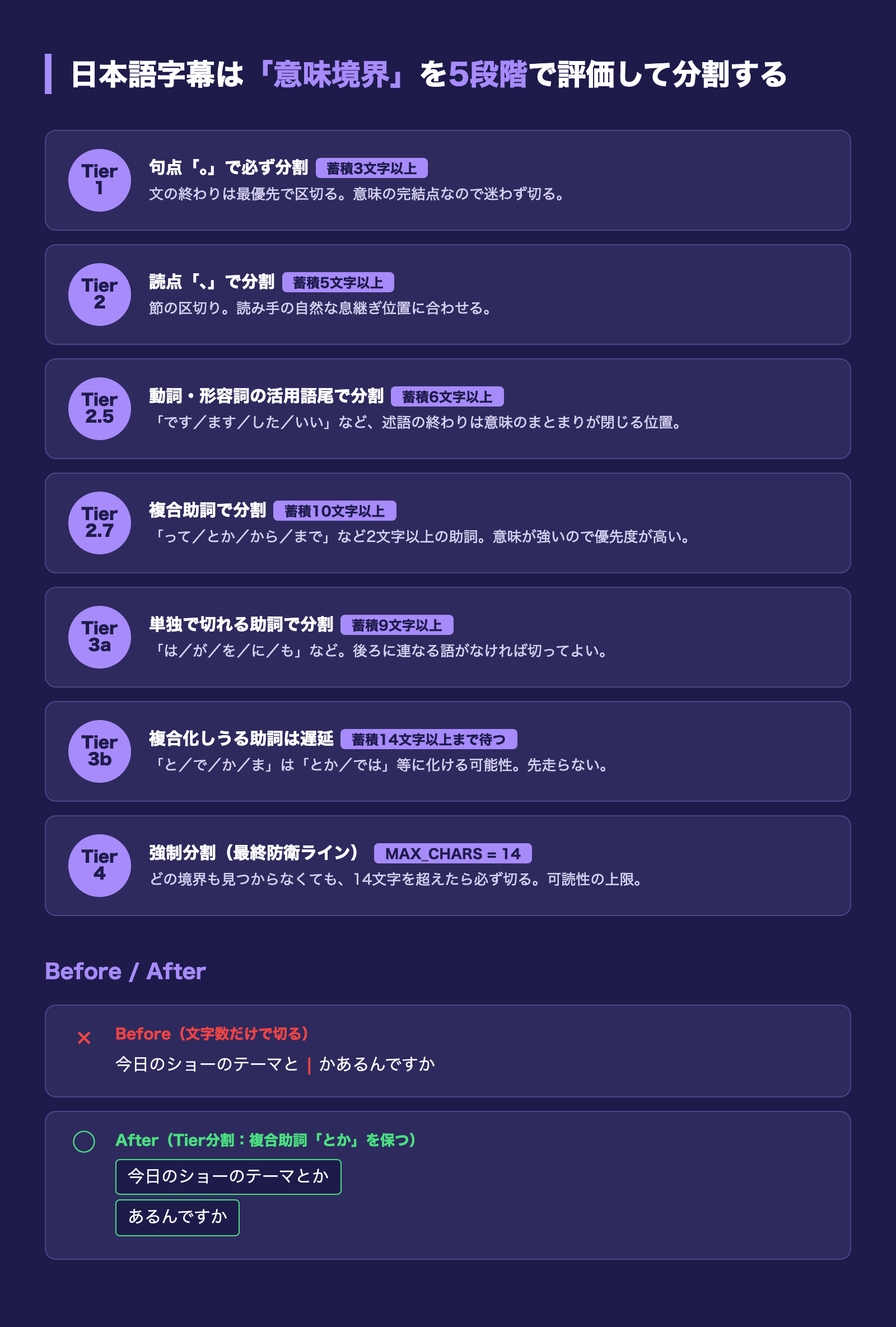
工夫3: 字幕の「意味境界優先」Tier分割
日本語の字幕は、英語と違って単純な単語区切りで切ると不自然になります。たとえば「今日のショーのテーマとかあるんですか」を文字数だけで切ると、「今日のショーのテーマと | かあるんですか」のように助詞の途中で分断されてしまうことがあります。
今回採用したのは、意味境界を7段階の優先度で評価するTier分割ロジックです。
- Tier 1: 句点「。」 — 蓄積3文字以上で必ず分割
- Tier 2: 読点「、」 — 蓄積5文字以上で分割
- Tier 2.5: 動詞・形容詞活用語尾 — 「です」「ます」「した」「いい」など、蓄積6文字以上
- Tier 2.7: 複合助詞 — 「って」「とか」「から」「まで」など、蓄積10文字以上
- Tier 3a: 単独で切れる助詞 — 「は・が・を・に・も・や・ね・よ・へ」、蓄積9文字以上
- Tier 3b: 複合化しうる助詞 — 「と・で・か・ま」は遅延(蓄積14文字以上まで待つ)。
との次にかが来て「とか」になるのを待つため - Tier 4: 強制 — MAX_CHARS=14に達したら問答無用で分割
このTier 3bが地味に効きます。素朴に「助詞で切る」ルールにするとと単独で切ってしまい「テーマと」「かあるんですか」になります。とを遅延させて「テーマとか」「あるんですか」と切り直す挙動を入れたことで、結果が一気に自然になりました。
工夫4: 字幕に「!」でテンションを足す vivid トーン
ライブパフォーマンス系のコンテンツでは、字幕にちょっとした熱量が欲しいことがあります。「そうなんですね。」より「そうなんですね!」の方が、明らかにテンションが伝わります。
これを自動でやるのが TONE = "vivid" 設定。次の置換ルールで字幕を仕上げます。
- 句点「。」→「!」に置換
- 宣言型語尾(「です」「ます」「でした」「ました」「いい」など)末尾には「!」を付与
- 疑問終止「か」末尾はそのまま(「ですか!」は不自然になるため)
結果として「皆さん今日お疲れ様です!」「最高に素敵でした!」「ありがとうございます!」のような、明るく前向きな字幕が生まれます。逆に落ち着いたトーンに戻したい案件用にはTONE = "neutral"で無効化できるよう、スイッチを残してあります。
工夫5: ffmpeg libass問題 ― brew標準では動かない
今回ハマったポイントを1つ共有します。Homebrew標準のbrew install ffmpegでは字幕焼き込みができません。
理由は、Homebrew版のffmpegが--enable-libassフラグなしでビルドされているから。libassを使うsubtitlesとassフィルタが含まれていないので、「字幕を焼き込もうとするとフィルタが見つからない」エラーになります。
解決策は、evermeet.cxの静的ビルドを使うこと。次のワンライナーで導入できます。
# 1. zipダウンロード(全機能入りの静的ビルド)
curl -L https://evermeet.cx/ffmpeg/get/zip -o /tmp/ffmpeg.zip
# 2. ~/Developer/ffmpeg-full/ に展開
mkdir -p ~/Developer/ffmpeg-full
unzip -o /tmp/ffmpeg.zip -d ~/Developer/ffmpeg-full/
chmod +x ~/Developer/ffmpeg-full/ffmpeg
# 3. PATHに追加(zshユーザー向け)
echo 'export PATH="$HOME/Developer/ffmpeg-full:$PATH"' >> ~/.zshrc
source ~/.zshrc
# 4. 動作確認(出力があればOK)
ffmpeg -filters | grep subtitles納品ドキュメントには必ずこの手順を載せています。「brew installで動くと思ってハマる」のは1人2人ではないはずなので、同様の自動化を組む方は早めに静的ビルドへ切り替えることをおすすめします。
工夫6: 対話姿勢の設計 ― 節目だけ止める、制作中は止めない
スキルの作り方には2つの極端があります。「全部勝手にやる」か「毎ステップ確認する」か。前者は失敗時のリカバリが効かず、後者はうるさくて作業が止まります。
今回採用したのは中間の設計です。スキル全12ステップのうち、確認待ちで止まるのはStep 0.5だけに絞りました。
タイミング | Claudeの振る舞い |
|---|---|
発火直後(Step 0) | 既存セッションあれば「新規 / 再実行」を質問 |
素材投入の案内(Step 0) | フォルダ作成 → 入れる場所を案内 → 「入れた」の合図を待つ |
素材検出+BGM選択(Step 0.5) | 素材一覧 + BGM 3択(ランダム / カテゴリ / 曲指定)を1セットで提示 |
manifest生成後(Step 1) | 採用したカット範囲・BGM・尺見込みを1ブロック報告、そのまま続行 |
制作中(Step 2〜8) | 各ステップ完了で1行進捗報告、確認待ちなし |
動画完成時(Step 8) | 「動画できました。続けて投稿キット作ります」と予告 |
全完了時(Step 12) | preview.mp4とcaption-kitの絶対パス + ターミナル全文表示 |
素材確認とBGM選択を1つの対話にまとめたのがポイント。「素材OKですか?」「BGMどうしますか?」と別々に聞くと2回確認待ちが発生しますが、まとめれば1回で済みます。「Aで」「bigbandで」「bigband-02で」のような自然な日本語回答でOKにしているので、操作の心理的負担も低めです。
運用に効いた小さな工夫
大きな技術的工夫の他にも、運用品質を上げるための細かい工夫がいくつか入っています。
中間ファイルを _work/ サブフォルダに分離
動画自動化は中間生成物が多くなりがちです。素のままだと output/2026-05-13/ に12〜15個のファイルが並んで、「どれが完成版?」が分かりにくくなります。
今回は中間ファイルをすべて_work/サブフォルダに移動し、ルート直下に見えるのはpreview.mp4とcaption-kit-*.mdの完成物2つだけにしました。設定ファイル(master.srt / manifest.json)も_work/に入れています。「触りたい時は触れるが、普段は隠れている」状態です。
業態BAN回避ワードフィルタ
動画自動化と並行して、SNS投稿時のコミュニティガイドライン違反リスクはクライアント側に重くのしかかります。今回はcaption-kitスキル側でハッシュタグの自動付与時にBANリスクの高いタグを自動的に除外する仕組みを入れました。性的・年齢制限を示唆するワードはすべてブロック対象、「ショーパフォーマンス」「アート」「カルチャー」寄りの言葉に自動で寄せます。
「ご自身のペースで」のトーン設計
納品物・資料すべてで「毎日◯本」のようなペース指定を入れていません。発信戦略は事業者本人が決めるもので、こちらが押し付ける性質のものではないからです。「素材が揃った日に作る、それで十分」というスタンスで設計しています。
導入後の見込み工数と運用
納品後、クライアントの作業時間は次のように見込んでいます。
- 素材を所定フォルダに入れる: 約5分
- Claudeの自動処理: 約1〜3分(動画の長さによる)
- SNSへの投稿(コピペ): 約5分
- 合計: 約15分(1本あたり)
これまで編集に1〜2時間かけて月1〜2本だったところを、無理なく必要なペースで出せる工数になりました。撮影後すぐ発信できる体制を持てるかどうかは、SNS運用の継続性に直結します。
同様の自動化を組む方への引き継ぎ
ショート動画自動編集パイプラインを類似業態(店舗・ライブパフォーマンス・教室・施術系等)で組む方への引き継ぎとして、ここまでの工夫を5つに圧縮するとこうなります。
- 素材の振り分けはファイル名ではなくフォルダで決める(間違えない構造)
- BGMはduckedモードで実装する(メリハリを音量で作る、ショー区間でbase音声ミュート)
- 日本語字幕は意味境界Tier分割で切る(単純な文字数カットは破綻する)
- ffmpegは静的ビルドを推奨(brew標準ではlibass非搭載)
- 確認は節目だけ、制作中は止めない(対話品質と作業効率の両立)
本記事で紹介した工夫は、すべてClaude Code上の「スキル」として再利用可能な形にまとめています。スキル機構自体の学び方や、私が普段どう自動化を組んでいるかについては、別の記事でも掘り下げています。

まとめ ― 動画編集の自動化は「素材設計」と「対話設計」が9割
動画編集の自動化と聞くと、字幕生成やBGMミックスのような技術的な要素に目が行きがちですが、実際に動く納品物に仕上げるには素材をどう整理してもらうかとクライアントとどう対話を組むかの2点の方が、はるかに重要でした。
素材設計でファイル名を考えなくて済むようにし、対話設計で確認待ちを最小にする。この2つが揃って初めて、毎日触っても苦にならないツールになります。技術的な作り込みは、その土台の上に乗せる装飾のようなものです。
動画コンテンツの発信を継続したいけれど編集に時間を取られすぎている方、Claude Codeで自社向け自動化パイプラインを組みたい方は、本記事の構造や工夫が出発点として使えるはずです。
「Claude Code を自分で使いこなしたい」「自社の業務に組み込みたい」
── そんな方は、まず初回無料相談でお話ししてみませんか。
御社の業務に合わせたClaude Code導入支援
「AIツールを導入したが、現場で使われない」を終わらせる。
業務課題のヒアリングから設計、ハンズオン実践、運用定着まで一貫して支援します。