Claude Codeナレッジ管理|セッション間で知見を失わない仕組み

Claude Codeを使っていて、こんな経験はないでしょうか。
- 新しいセッションを開くたびに「うちはPostgreSQLです」「Next.js App Routerです」と説明し直す
- 先週フィードバックしたはずのルールが、今週はもう反映されていない
- 過去に解決したバグと同じ問題を、また1から調べ始める
これは「AI amnesia(AI記憶喪失)」と呼ばれる現象です。Claude Codeのモデル自体は優秀ですが、セッションが変わると記憶がリセットされる。だから毎回、同じ説明を繰り返すことになります。
私は株式会社Fyveで複数のクライアント案件を回す中で、このAI amnesiaに何度も苦しめられました。この記事では、マークダウンファイルだけでClaude Codeに「プロジェクトの記憶」を持たせる仕組みを、実運用の設計図とともに共有します。
まずはマークダウン4ファイルから始められる
プロジェクトメモリの基本形は非常にシンプルです。RAGもベクトルDBも不要。マークダウンファイルを数個置くだけで、Claude Codeの挙動は劇的に変わります。
- key_facts.md:技術スタック、環境変数、API設定など。Claudeが設定値を「推測」するのを防ぐ
- decisions.md:設計判断の記録。「なぜこのライブラリを選んだか」を残すことで、矛盾した提案を防ぐ
- bugs.md:過去のバグと解決策。同じ問題を2度調べる時間をゼロにする
- issues.md:進行中の課題と完了したタスク。プロジェクトの時系列文脈を与える

これだけで、新セッションのたびに技術スタックを説明し直す必要はなくなります。Claude Codeは起動時にCLAUDE.mdを自動読み込みするので、ここから各ファイルを参照させる設計にすれば、セッション間の記憶が途切れなくなります。
4ファイルでは足りなくなった理由
ただし、実務でこの仕組みを半年以上回してみると、4ファイルの限界が見えてきました。
最初の問題はファイルの肥大化です。プロジェクトが進むにつれ、bugs.mdやdecisions.mdがどんどん長くなる。Claude Codeは長いコンテキストの中間部分の情報を見落としやすいことが研究でも示されており、せっかく書いた知見が無視されるケースが出始めました。
次の問題は分類の曖昧さです。「このフィードバックはbugs.mdに書くべきか、decisions.mdに書くべきか」と迷うことが増え、情報の置き場所がバラバラになりました。
そして最大の問題は、知見の蓄積が手動だったことです。セッションで得た知見を毎回自分でファイルに書き足す——この手間が地味に大きく、忙しいと書き忘れる。結局、記憶が断片的になっていました。
多層ナレッジ設計:振り分けテーブルという発想
これらの課題を解決するために、私は知見の種類ごとに蓄積先を定義する「振り分けテーブル」を設計しました。
- 案件実績・エピソード → 実績・経験データベース(data/)
- AIツールの使用知見 → AI開発ツール知見データベース(data/)
- コーディング規約の変更 → rules/coding.md
- 記事執筆ルールの変更 → rules/article-writing.md
- ビジネス方針の変更 → rules/business-context.md
- 分類しにくい一時的な知見 → learnings/YYYY-MM.md(月単位で蓄積)
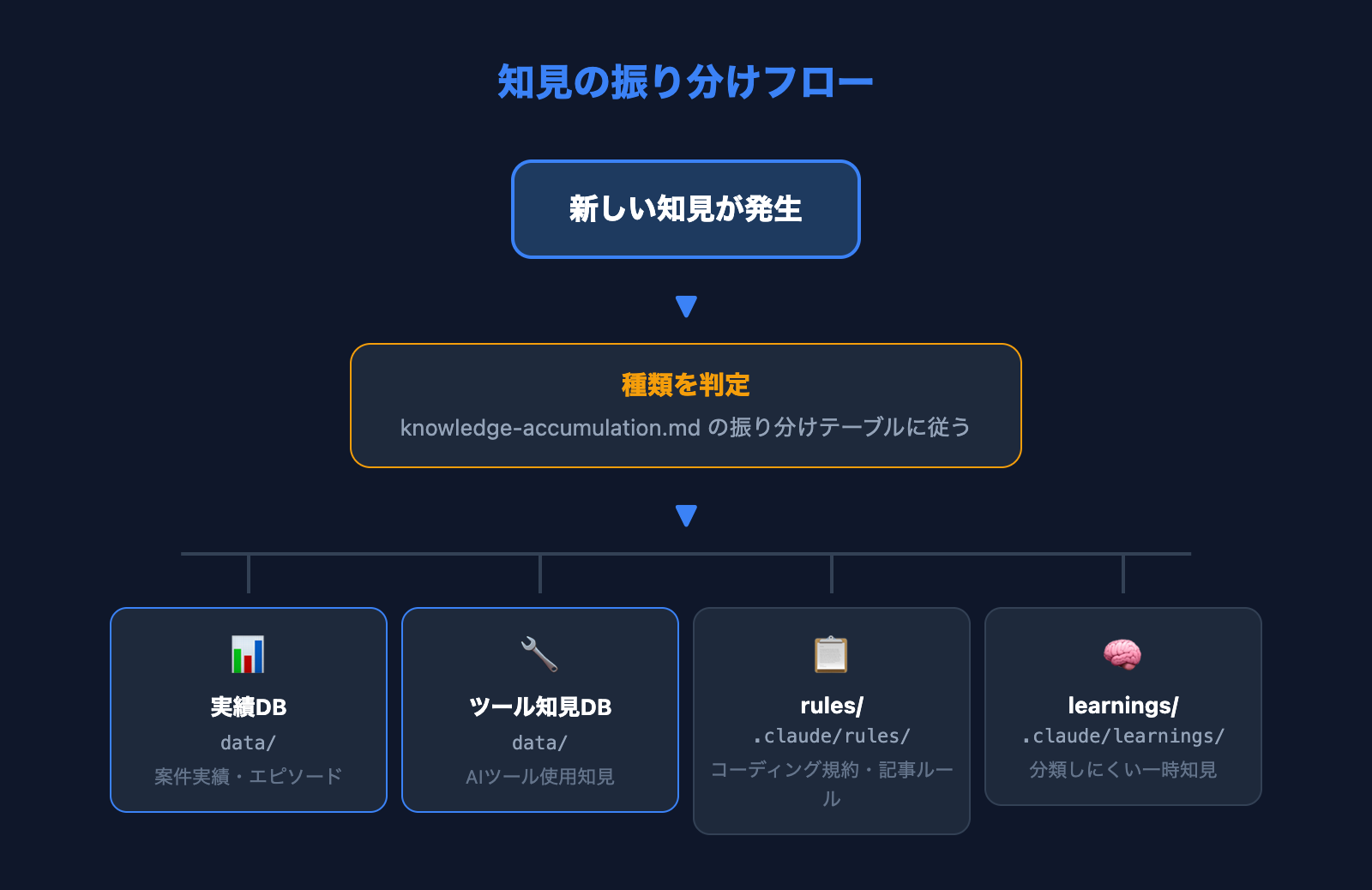
このテーブルをknowledge-accumulation.mdというルールファイルに定義しておくことで、Claude Code自身が「この情報はどこに保存すべきか」を判断できるようになります。4ファイルのフラットな構造から、目的別に整理された多層構造への進化です。
learnings/ → rules/への昇格フロー
多層設計の中で特に重要なのが、一時知見の受け皿であるlearnings/の運用です。
セッション中に得た知見のうち、すぐに分類できないものはlearnings/YYYY-MM.mdに一時保存します。各エントリには日付・カテゴリ(tech / business / feedback / debug / idea)・内容を記録。
そして月末に棚卸しを行います。
- 重要な知見 → rules/や正式なデータベースに昇格
- 不要な知見 → 削除
たとえば、セッション中に「この表記ルールを守って」とフィードバックした内容が、最初はlearnings/のfeedbackカテゴリに記録されます。月末の棚卸しで同じフィードバックが繰り返されていれば、rules/article-writing.mdに正式ルールとして昇格させます。
この「一時蓄積→棚卸し→正式ルール化」のフローによって、プロジェクトの知識が自然に整理・成長していきます。
自動蓄積:「答えたら即保存」の仕組み
振り分けテーブルだけでは、まだ一つ課題が残っていました。ヒアリングで得た情報の保存が漏れる問題です。
たとえば、SEO記事を書くために私の実体験をヒアリングしたとします。「この案件ではこういう課題があって、こう解決した」と答える。その情報は記事には反映されるのですが、データベースへの蓄積が抜け落ちることがありました。次に似たテーマの記事を書くとき、同じ質問をもう一度されることになります。
そこで、蓄積ルールに「ユーザーが質問に回答した場合も即追記する」という自動トリガーを追加しました。「保存して」と言われるのを待たず、一次情報を含む回答を受け取った時点で該当ファイルに自動追記する仕組みです。
これにより、ヒアリングで出た情報が自動的にデータベースに蓄積され、次回以降のセッションで即座に参照できるようになりました。手動の書き忘れがゼロになったのは、運用上の大きな転換点でした。
Auto Memoryの限界と補完策
Claude CodeにはAuto Memory機能があり、~/.claude/CLAUDE.mdにセッションの学びを自動記録してくれます。便利ですが、いくつかの限界があります。
- 振り分けができない:全てがグローバルCLAUDE.mdに書かれるため、プロジェクト固有の知見も全セッションに影響する
- 肥大化する:Auto Memoryが大きくなるほど、全セッションのコンテキスト消費が増える
- 構造化されない:フラットに追記されるため、情報の検索性が低い
対策として、Auto Memoryに任せきりにせず、前述の振り分けテーブルで明示的に蓄積先を定義しています。Auto Memoryは「補助的な記録」として残しつつ、プロジェクトの中核知見は構造化されたファイルに蓄積する。この二段構えが、現時点での最適解です。
複利で効く:使い込むほど精度が上がる
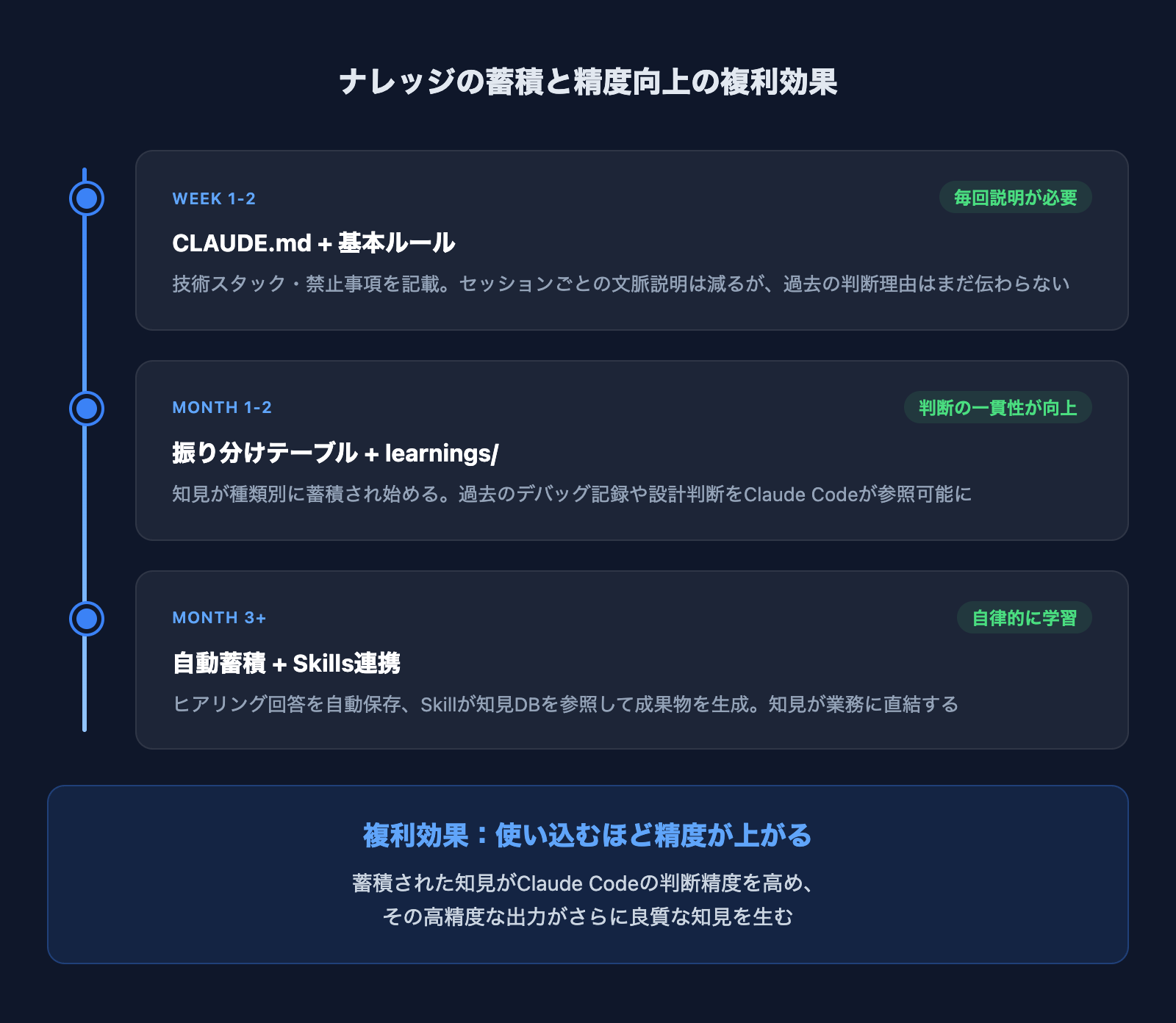
このナレッジ管理の仕組みで最も実感しているのは、複利効果です。
最初の1〜2週間は、CLAUDE.mdと基本ルールで「毎回の説明」を減らしただけでした。しかし1ヶ月、2ヶ月と知見が蓄積されるにつれ、Claude Codeの出力精度が目に見えて上がっていきます。
具体的な例を挙げると、SEO記事の執筆です。初期は毎回「田嶋の実績データベースを見て」「記事の表記ルールを確認して」と指示していました。今ではキーワードを渡すだけで、過去の実績を自動参照し、表記ルールを守り、既存記事との重複を避けた記事が出てきます。
蓄積された知見がClaude Codeの判断精度を高め、その高精度な出力がさらに良質な知見を生む。使い込むほどプロジェクトが「賢く」なっていく感覚は、まさに技術的負債の逆——ナレッジの複利です。
蓄積のルール:何を保存し、何を保存しないか
何でも保存すればいいわけではありません。知見蓄積には3つのルールを設けています。
- 一次情報のみ蓄積する:推測や一般論は保存しない。ユーザーから得た事実だけを記録する
- 重複させない:同じ情報を複数ファイルに書かない。メンテナンスの手間と情報の不整合を防ぐ
- 既存フォーマットを守る:追記する際は各ファイルの構造を壊さない。データベースの一貫性が命
また、知見ファイルが肥大化したらファイル分割やSkill内での必要部分だけの読み込みで対応します。トークン管理の詳細はMax 5xプランのレビュー記事で解説しています。
まとめ:マークダウンだけでClaude Codeは「学習」する
Claude Codeのナレッジ管理に必要なのは、RAGでもベクトルDBでもありません。マークダウンと振り分けルールだけです。
- 4ファイルから始める:key_facts / decisions / bugs / issuesで基本的な記憶を持たせる
- 振り分けテーブルで多層化する:知見の種類ごとに蓄積先を定義し、構造化する
- learnings/ → rules/の昇格フローで知識を自然に成長させる
- 自動蓄積トリガーで手動の書き忘れをゼロにする
- Auto Memoryに頼りすぎない。明示的な振り分けで補完する
設定ファイルの工夫だけで、Claude Codeは「使うたびに賢くなるツール」に変わります。あなたのプロジェクトでも、まずは4ファイルから試してみてください。
御社の業務に合わせたClaude Code導入支援
「AIツールを導入したが、現場で使われない」を終わらせる。
業務課題のヒアリングから設計、ハンズオン実践、運用定着まで一貫して支援します。