Date
2026/05/09
Category
AI業務効率化
Title
AIに業務情報を入れて大丈夫?主要4社の学習ポリシー

「サーバー経由」と「学習利用」は、別の話です
AIに業務情報や顧客データを入力するとき、最初に頭をよぎるのは「これって学習に使われるんじゃないか」という不安です。実際に補助金コンサルタントの方とのセッション準備で、まさにこの質問を受けました。「AIへの学習をオフ設定にしているので問題ないと思っていますが、本当にそうですか」と。
結論からお伝えすると、ここには2つの異なる事象が混在しています。
- サーバーへのデータ送信:AIが応答を生成するためには、入力データを必ずAIサービスのサーバー(OpenAIならOpenAI、AnthropicならAnthropic)に送る必要がある。これは「学習オフ」設定でも止まらない
- モデルへの学習利用:送信されたデータを次世代モデルの訓練データセットに含めるかどうか。これは設定や契約で制御できる
「学習オフ」が保証するのは後者だけです。前者は推論処理のために原理的に止められません。この区別をしないまま判断すると、「学習オフだから安心」という誤った安心感や、「サーバーに送られる時点でアウト」という過剰な警戒の両方を生みます。
本記事では、主要4社(ChatGPT・Claude・Gemini・Microsoft 365 Copilot)のデータ取扱いポリシーを一次情報ベースで整理し、ビジネス利用での判断基準をまとめます。

ChatGPT(OpenAI)のデータ学習ポリシー
個人版(Free / Plus)はデフォルトで学習に使われる
ChatGPT の Free プランと Plus プランは、入力した会話がモデル改善に使われるのがデフォルト設定です。OpenAI のヘルプセンターでは、Settings から「Data Controls」→「Improve the model for everyone」のトグルをオフにすることで、新規の会話を学習対象から外せると明記されています。
「Temporary chat」(一時チャット)機能を使った会話は学習に使われず、30日後に自動削除されます。ただしフィードバック(thumbs up / down)を送った会話については、その会話自体がレビュー対象になる点には注意が必要です。
業務版(Team / Enterprise / API)は学習に使われない
ChatGPT Team、ChatGPT Enterprise、API の3つは、入力データがモデル学習に使われないことが契約(DPA)で明確に保証されています。OpenAI Enterprise Privacy のページでも「By default, OpenAI does not train on any inputs or outputs from our products for business users」と明示されています。
API の標準データ保持期間は30日です。さらに厳しい要件が必要な場合は Zero Data Retention 契約も用意されており、エンタープライズ要件として申請できます。
業務でお客様データを扱うなら、無料版や Plus ではなく Team / Enterprise / API を選ぶのが基本判断です。「個人版で学習オフ」では、契約上の保護という観点では不十分です。
Claude(Anthropic)のデータ学習ポリシー
消費者プランの重大な変更:2025年9月28日からopt-out方式に
2025年8月28日、Anthropicは消費者プランのプライバシーポリシーを大きく変更すると発表し、2025年9月28日から実際に適用しました。Free・Pro・Max プランの会話データは、デフォルトでモデル改善に使われるようになり、学習を拒否するには明示的に opt-out 設定をする必要があります。
あわせて、データ保持期間も変わりました。
- opt-in した場合(デフォルト):5年間保持され、モデル学習に使われる
- opt-out した場合:30日保持で、学習に使われない(従来と同じ)
この変更は、これら消費者プランの認証情報で起動した Claude Code にも適用されます。ここがやや盲点です。Claude Code のターミナルから補助金書類のドラフトを生成するような使い方も、消費者プランで使っている限りは学習対象に入る可能性があります。Claude Code = 安全と思い込まず、認証元のプランを確認する必要があります。
商用プラン(API / Claude for Work / Government / Education)は学習に使われない
商用利用に関しては、Anthropic の Commercial Terms(2025年6月17日付)で明確に「Anthropic may not train models on Customer Content from Services」と規定されています。ここで言う Customer Content には、入力プロンプトも生成された Output も含まれます。
つまり、Anthropic API を直接叩く場合、Claude for Work(チーム / エンタープライズ)を契約している場合、Claude for Government / Education を使っている場合は、契約上学習に使われません。
業務で機密性のある情報を扱うなら、消費者プランではなく API か Claude for Work を選ぶ。これが Claude を使う場合の基本判断です。
Gemini(Google)のデータ学習ポリシー
個人 Google アカウント版は学習に使われる(人間レビューも一部実施)
Google Gemini の個人アカウント版は、「Gemini Apps Activity」設定が ON の状態がデフォルトです。Google のヘルプページ(2026年5月5日更新)によれば、この設定が ON のとき、会話データは保存され、モデル改善に使われます。さらに一部の会話は人間レビュアーによって検査されます。
レビュー済みデータはアカウントから切り離された状態で最大3年間保持されます。デフォルトの保持期間は18ヶ月で、3ヶ月・36ヶ月・無期限・Activity OFF(72時間で削除)の4択から変更できます。
Gemini Apps Activity を OFF にすれば、会話は72時間で削除され、学習にも人間レビューにも使われません。ただし Activity OFF の場合、過去の会話を踏まえた返答などの一部機能が使えなくなる点は引き換えになります。
Google Workspace 版(法人契約)は別ポリシー
仕事用や学校用の Google アカウントで Gemini を使う場合、データの取扱いは別ポリシーになります。Workspace 契約に紐づく Gemini は、組織のデータがモデル学習に使われない仕様です。
個人アカウントで業務利用しているケースは、ポリシー上のリスクが高い状態です。組織として Gemini を使うなら Workspace 契約が前提と考えるのが安全です。
Microsoft 365 Copilot のデータ学習ポリシー
テナントデータは学習に使われない、サービス境界内で処理
Microsoft 365 Copilot は、組織のデータ(Microsoft Graph 経由でアクセスする Word / Outlook / Teams / SharePoint のコンテンツ)を、基盤 LLM の学習に使わないと公式ドキュメント(2026年3月9日更新)で明記されています。
処理は Microsoft 365 サービス境界内で完結し、Azure OpenAI Service が使われます。一般公開されている OpenAI(つまり ChatGPT のバックエンド)ではなく、Microsoft の管理下にあるインスタンスで動く点が重要です。Azure OpenAI 側でもプロンプトや応答はキャッシュされません。
EU データ境界・コンプライアンス対応
Microsoft 365 Copilot は EU Data Boundary に対応しており、EU ユーザーのトラフィックは EU 域内で処理されます。GDPR、ISO 27001、HIPAA、ISO 42001(AI管理システムの国際規格)に準拠しています。
また、Customer Copyright Commitment という保護も特徴的です。Microsoft Copilot の生成物が第三者から著作権侵害を訴えられた場合、Microsoft が顧客を防御し、判決による損害賠償を肩代わりします。これは AI 生成物の法的リスクを企業から取り除く強力な仕組みです。
4社横断:プラン別データ学習ポリシー比較
ここまでの内容を一覧で整理すると、判断軸が見えやすくなります。
サービス | 個人版(消費者プラン) | 業務版(商用プラン) |
|---|---|---|
ChatGPT | Free / Plus:学習に使われる(opt-out可) | Team / Enterprise / API:契約上学習されない |
Claude | Free / Pro / Max:学習に使われる(2025年9月以降、opt-out可・5年保持) | API / Claude for Work / Gov / Edu:Commercial Termsで学習禁止 |
Gemini | 個人アカウント:学習・人間レビューに使われる(Activity OFFで停止可) | Google Workspace:組織データは学習されない |
Microsoft Copilot | Copilot Pro(個人):別ポリシー要確認 | Microsoft 365 Copilot:テナントデータは学習されない |
共通する原則は明確です。業務利用は必ず商用プランを使う、消費者プランで「学習オフ」設定だけに頼らない。これが4社共通の基本判断軸です。

業務でAIを使うときの4つの判断基準
1. 個人版と業務版の境界を理解する
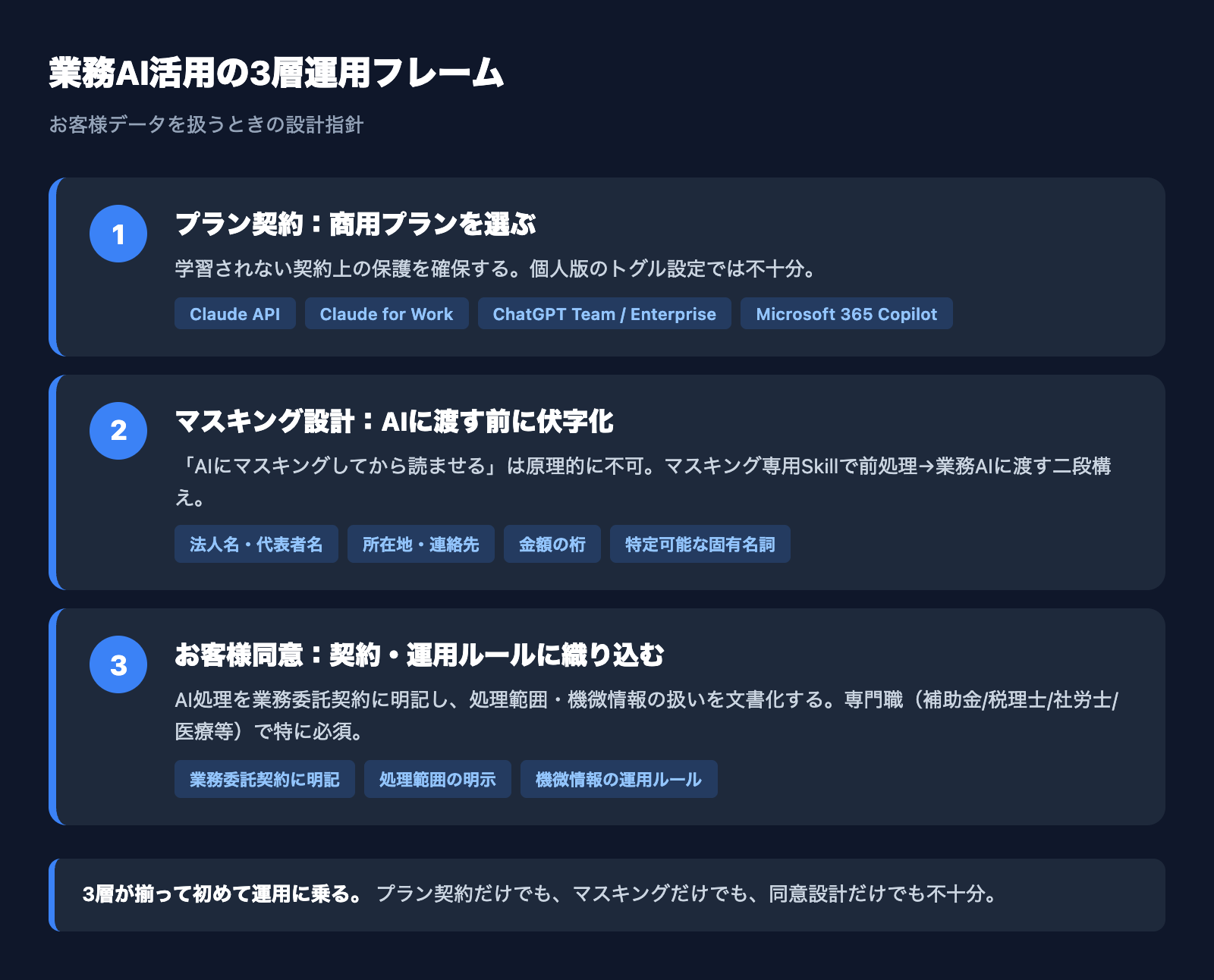
すべてのサービスで、個人版(Free / Plus / Pro / Max / 個人 Google アカウント)と業務版(Team / Enterprise / API / Workspace / Microsoft 365 商用契約)では、データ取扱いポリシーが根本的に異なります。お客様データや機密データを扱うなら、必ず業務版を契約するというのが大前提です。
「個人版で学習オフ」は契約上の保護がなく、ポリシー変更時にも影響を受けやすい不安定な状態です。Anthropic の2025年9月の変更がまさに典型例で、個人プランでは設定がデフォルトで覆る可能性があります。商用プランは契約書(Commercial Terms)で禁止されているため、こうした変更に直接さらされません。
2. 「学習オフ」は完璧な保護ではない
学習オフ設定は「将来のモデル訓練に使われない」を保証するもので、「サーバーに送られない」とは別の話です。推論処理のために、データは必ず AI サービスのサーバーを経由します。これを止めるには、ローカルで動く LLM(Llama や Mistral 等のオープンウェイトモデル)を使うしかありません。
ただし、商用プランの場合は「学習に使われない × データ保持期間が短い × 契約上の機密保持義務」の3点セットで保護されるため、実務的にはこのレベルで十分です。
3. マスキングは「AIに渡す前」にやる必要がある
「AIに『マスキングしてから読んで』と指示すればいい」という発想を持たれる方は実は多いのですが、これは原理的に成立しません。AI がファイルを読み込んだ瞬間に生情報がコンテキスト(プロンプト)に入ってしまうため、マスキングは AI に渡す前に終わっていなければなりません。
運用上の代替案としては、「マスキング処理自体を別工程として AI に任せる」設計があります。たとえば、生のファイルをまず「マスキング専用 Skill」に通して固有情報を伏字化し、その出力を本来の業務 AI に渡す、という二段構えにすれば、本来の業務処理の AI には伏字化済みデータしか届きません。Claude Code の Skill 機構や、API での前処理ステップとして組み込めます。
4. クライアント業務でのAI利用は、お客様の同意設計とセットで考える
お客様の事業情報を AI に入れて業務を回す場合、自分のデータ取扱いポリシーだけでなく、お客様への同意取得をどう設計するかが本質的な論点です。「業務で AI を使う旨を契約書に記載する」「AI 処理する範囲を明示する」「機微情報は事前にマスキングする運用を組み込む」など、運用ルール側の整備が必要になります。
この観点は、補助金コンサルタント、税理士、社労士、弁護士、医療従事者など、お客様の機密情報を扱う専門職で特に重要です。私自身も、補助金コンサルタントの方からの「事業計画書の自動化を Claude Code で組みたい」という相談を受けたとき、最初に議論したのはマスキング工程の設計と、お客様への同意取得をどう運用に組み込むかでした。商用プラン契約だけでは足りず、クライアント側のルール整備とセットで初めて運用に乗ります。
実務での運用 — 案件の機密性に応じて使い分ける
私自身の AI 開発業務では、案件の機密性レベルに応じてツールと設定を使い分けています。
- 機密性が高い案件:Anthropic API 直叩き(Commercial Terms 配下)、または法人契約の Claude for Work で運用。Claude Code を使う場合も Anthropic API キー認証で起動し、消費者プラン認証は使わない
- 機密性が低い案件・検証用:消費者プラン(Pro / Max)で運用。ただし2025年9月以降は学習に使われる前提で、入力する情報の機密度を判断したうえで使う
- プロジェクト単位で permissions(allow / deny)を調整:Claude Code の MCP 連携やツール許可も、案件の機密性に応じて allow / deny を変える。一律のルールではなく、案件ごとの判断
判断軸は、「お客様データが含まれるか」「公開してはいけない情報があるか」「学習に使われた場合のビジネスインパクトはどの程度か」の3点です。この3点をプロジェクト立ち上げ時に整理しておけば、後段の運用判断は機械的に決まります。
まとめ — ポリシーを正しく理解して、業務AI活用に踏み出す
AI に業務情報を入れていいかどうかという問いは、「AIを使うべきか / 使うべきでないか」の二択ではなく、「どのプランで、どう運用すれば業務に組み込めるか」という設計の問題です。
主要4社のポリシーは公式ドキュメントとして公開されており、誰でも一次情報にアクセスできます。プランを選ぶこと、設定を確認すること、マスキング運用を組み込むこと。この3点で、業務での AI 活用は実務的な実装段階に進めます。
「サーバー経由」と「学習利用」を切り分けて理解した上で、商用プラン × マスキング設計 × お客様への同意取得という3層構造で運用を組む。これが2026年時点の業務 AI 活用の現実解です。
Claude Codeのデータは学習に使われる?プラン別ポリシーと競合比較


「AIで何ができるか分からない」「興味はあるが業務に活かせていない」
── そんな方は、まず1回お話ししてみませんか。
→ AI業務効率化のスポット相談(30分 ¥6,000〜・初回限定)
「手作業」が当たり前の業務、
AIで変えませんか?
御社の業務フローに合わせた完全カスタムのAIシステムを開発し、記録・書類作成・データ管理を自動化します。
- ✓ 月数十時間の業務削減を実現
- ✓ 補助金で導入費用の50〜75%を補助
- ✓ 無料診断受付中

Company
株式会社Fyve
Address
〒810-0001
福岡県福岡市中央区天神4丁目6-28
天神ファーストビル7階
Tel
080-1460-2728
info@fyve.co.jp